Hi Steemers!

This is my second post here, on Steemit and I extremely excited to contribute to this amazing community. In my introduction there were some discussions and debates on the fact, that I used big words of machine learning and #Blockchain just to attract attention and have nothing to do with the topic itself. Therefore I devote this post to #MachineLearning algorithms. Once again I would like to draw your attention to the fact that I am not an expert in this field of knowledge and it’s just an area of my interests. In other words I'm on the beginning of this fascinating scientific journey but would like to share some thoughts that I hope you’ll find interesting.
Recently I have learned about the Prisma app . At that time, its already used by most of my friends and even my stepfather, but initially it was released only for iOS, and as the owner of android, I had to patiently wait for it.

If you don’t know, Prisma is the app for processing photos. According to the analysts of "App Annie", Prisma has become one of the most downloaded apps in ten countries within just nine days: Russia, Belarus, Estonia, Moldova, Kyrgyzstan, Uzbekistan, Kazakhstan, Latvia, Armenia, Ukraine.
App description in the Google Play states: "Prisma transforms your photos into works of art using the styles of popular artists: van Gogh, Picasso, Levitan, as well as known patterns and ornaments. A unique combination of neural networks and artificial intelligence helps to transform your memorable moments into masterpieces."
From the first glance it seems magical, but your photos really become as a work of art... It is a Pity that there was no such a technology when "A Scanner Darkly" movie with Keanu Reeves was filmed. The artists had to manually draw each frame in the movie. It was extremely exhausting and required a lot of efforts.
Once I was interested in Prisma, I decided to drill down and came across an article written by researchers from Stanford. Guys from Department of Computer Science describe an algorithm that allows to preserve the sense of the image by changing the performance! This article is called "Perceptual Losses for Real-Time Style Transfer and Super-Resolution" (Justin Johnson, Alexandre Alahi, Li Fei-Fei).
Task which is solved by the algorithm is: to convert the first image in such way that its style was similar to the second, while retaining the meaning. The image whose style we use is called Target Style. The image which we transform called Target Content. Note that the neural network is trained separately for different Style Target images.
It is obvious that the convolutional neural network is used to transform the images (Image Transform Net) and we need to train this network. Initially I didn't understand how... How to explain to computer which images have a similar styles and content?
System overview from the article:
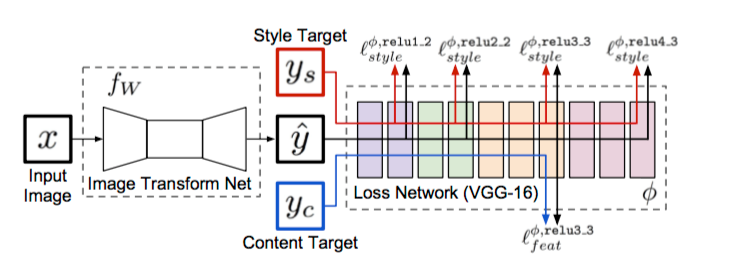
"We train an image transformation network to transform input images into output images. We use a loss network pretrained for image classification to define perceptual loss functions that measure perceptual differences in content and style between images. The loss network remains fixed during the training process." - oh, it's cool! They uses second network to define the images style similarity!
In the process, neural networks generate many "features maps". Features map - three-dimensional array of numbers.These structure contain information about the image in an accessible form for machine. The main idea is to use them to determine the style similarity of images. But they are already used to determine the class of the image, as we can use them in different way? You can use their correlation! Authors propose to encode the style by Gram Matrix:
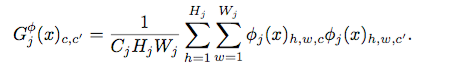
X is the input image, C_j, H_j, W_j - size of the j-th features map, \Phi_j(x) - j-th features map. The difference between the styles of two images can be determined as the squared Frobenius norm of the matrix diff:
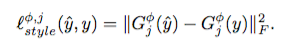
We can easily calculate the similarity of styles on j-th layer. To use one is not enough, you need to use many features map. Author used four outputs of convolutional layers.
We are done with the Style Losses problem, and it’s time to solve Perceptual Loss problem. For solving this problem authors introduce another metric (MORE METRICS!), that allow to determine difference between the contents. Now, we don’t need Gram Matrix, we just need a simple vector norm:
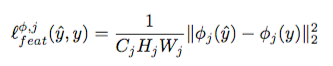
Minimizing the total losses get us properly trained Transform Net. Notice that the Transform Net is a convolutional neural network.
History. Pioneer of this problem is Gatys, and Stanford guys often refer to him. His last work is devoted to the transformation of style by retaining colors.
What about Prisma? It may use other architectures of neural network, but the concept is the same.