Yesterday I decided to parse the steem blockhain to see who are the most voted authors by whales. This statistics is for the timeframe of Aug 16 - Aug 23 (end of day).
First of all, most of what I did is heavily inspired from work done by @bitcalm @furion, @heimindanger and @trogdor. @xeroc - this would have not been possible without you. So, thank you fellas!
Here's a breakdown of the process.
First I went to steemwhales.com and took ~ 30 usernames (whales) from the first three pages. I considered the number of posts as well as the estimated value of the account.
I wanted to see who these users were voting the most, between Aug. 16 and Aug. 23. So, I parsed all the blocks in this timeframe. In my parsing, I dis-considered the votes made on comments (if permlink[:3] != "re-"). So, only post votes have been included.
It took about three hours to complete the process. I guess I was hammering the server last night. Mi scusi guys!
I don't know why, but I feel I have to say this.
This analysis display the most voted authors but it only considers whale votes as they carry heavy weight. If I were to have classified the most voted authors including all votes from all users, the situation may have been different.
That said, let's see the stats.
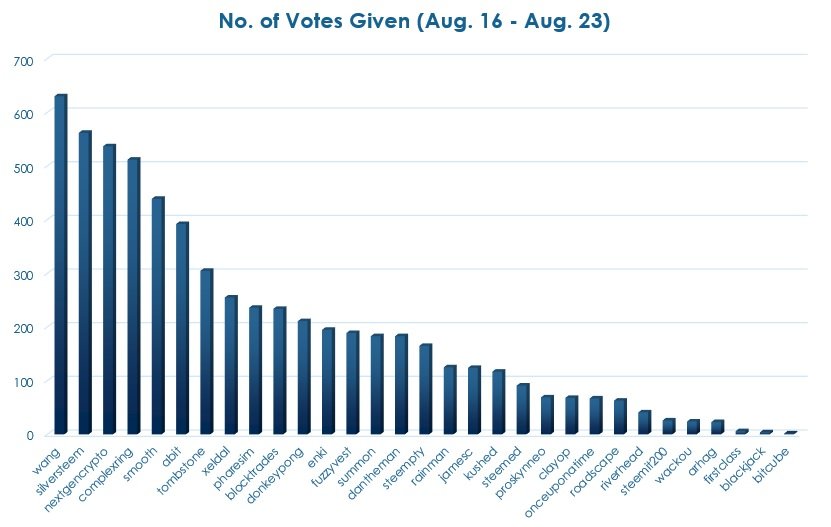
Number of Votes Given By Whales - Plot
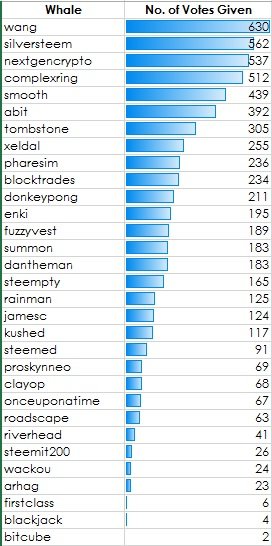
Number of Votes Given By Whales - Table View
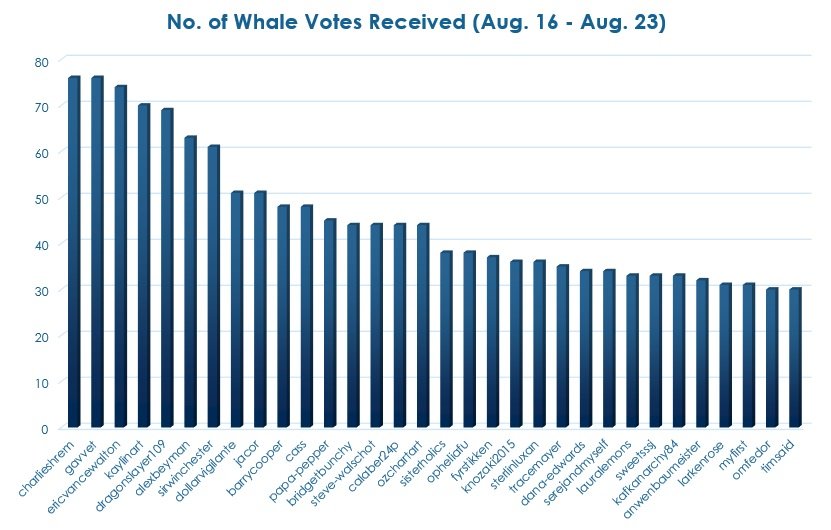
Number of Whale Votes Received by Authors - Plot
Number of Whale Votes Received by Authors - Table View
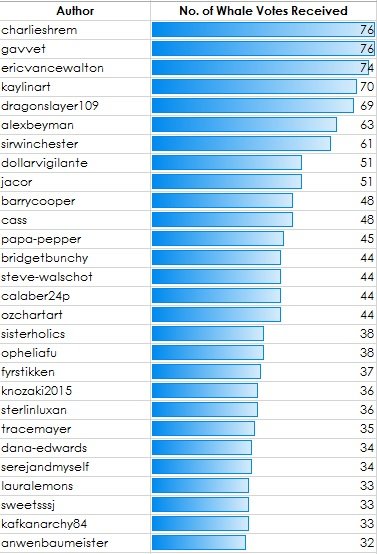
The list with the number of whale votes received by authors is more than 1,000 rows long. If you want to check if your name is on the list (and the number of votes you received), you can get the spreadsheet here.
As you can see, the whales have been pretty generous with their votes, despite what some users may think. @wang @silversteem @nextgencrypto and @complexring giving more than 500 votes in 7 days. I don't think I gave so many votes myself in this time period. Should I make future analyses of the same kind, I assume the situation will be even more insightful. Looking into the weight of each vote could provide another layer of comprehension.
What can aspiring authors take away from this?
Well, I'm not here to make suggestions; I only wanted to display a simple analysis. But I know that looking at the style of some authors and getting into their habits can be helpful and inspiring if you want to make it big.
In fact, I made a Q&A yesterday with one of the top authors on the platform - Eric Vance Walton. He describes in detail his steemit journey, his approach to daily writing, as well as his future goals with the platform. You can check it out here.
The Code
Glad you asked. It's a quick, messy draft. But it did its job. I'm sure it can run more efficiently with a little bit of housekeeping.
# thanks to @furion @bitcalm @xeroc and @trogdor for inspiring the code
from steemapi.steemnoderpc import SteemNodeRPC
rpc = SteemNodeRPC('ws://node.steem.ws')
from collections import Counter
import csv
# August 16 - beginning of the day - block 4117027
# August 23 - end of the day - bock 4341995
voters = ['blocktrades', 'jamesc', 'smooth', 'dantheman', 'tombstone', 'summon',
'steemed', 'rainman', 'wang', 'complexring', 'riverhead', 'roadscape',
'nextgencrypto', 'silversteem', 'donkeypong', 'proskynneo', 'blackjack',
'firstclass', 'enki', 'clayop', 'wackou', 'steemit200','kushed', 'xeldal',
'arhag','fuzzyvest','pharesim','steempty', 'bitcube','onceuponatime','witnes.svk'
,'abit']
voterlst = []
authorlst = []
permlinklst = []
# parsing the blocks between Aug 16 - Aug 23 (end of day)
for i in range(4117027, 4341995):
dys = rpc.get_block(i)['transactions']
for tx in dys:
for operation in tx['operations']:
if operation[0] == 'vote' and operation[1]['voter'] in voters:
voter = operation[1]['voter']
author = operation[1]['author']
permlink = operation[1]['permlink']
# we're looking for votes on posts, not on comments
if permlink[:3] != "re-":
voterlst.append(voter)
authorlst.append(author)
voteCounts = Counter(voterlst)
authorCounts = Counter(authorlst)
# indexing results for voters (name + votes given)
writefileV = open('voterresults.csv', 'w', newline='')
writerV = csv.writer(writefileV)
for vkey, vcount in voteCounts.items():
writerV.writerow([vkey, vcount])
# indexing results for authors (name + votes received)
writefileA = open('authorresults.csv', 'w', newline='')
writerA = csv.writer(writefileA)
for akey, acount in authorCounts.items():
writerA.writerow([akey, acount])
You can also get the code from github.
If you have ideas for other analytics of this kind, I'm open to suggestions.
To stay in touch, follow @cristi
#analytics #programming #statistics
Cristi Vlad, Self-Experimenter and Author