早前o哥 @oflyhigh介紹過怎樣用SteemData拿數據,這裏就介紹一下另一個提數的方法-Steemsql

(圖片來源: https://goo.gl/vXQKbo)
其實SQL就是一種用來專門用來查數據的語言,Microsoft Access寫query的時候也是用這個東西,而且基本用法一點都不難。Steemsql就是一個數據庫,讓大家能用SQL提取Steemit的數據。
怎樣連上Steemsql
要用Steemsql來查數據得先有一個Studio,比如可以用Microsoft SQL Server Management Studio (在官網可以下載),但我自己用的是Valentina Studio (在這可以下載: https://www.valentina-db.com/en/studio/download/current),下稱VS。
下載並安裝以後首次打開VS它會要你輸入序號,到它網站去免費申請一個帳號後就可以拿得到了。打開以後應該是這個樣子
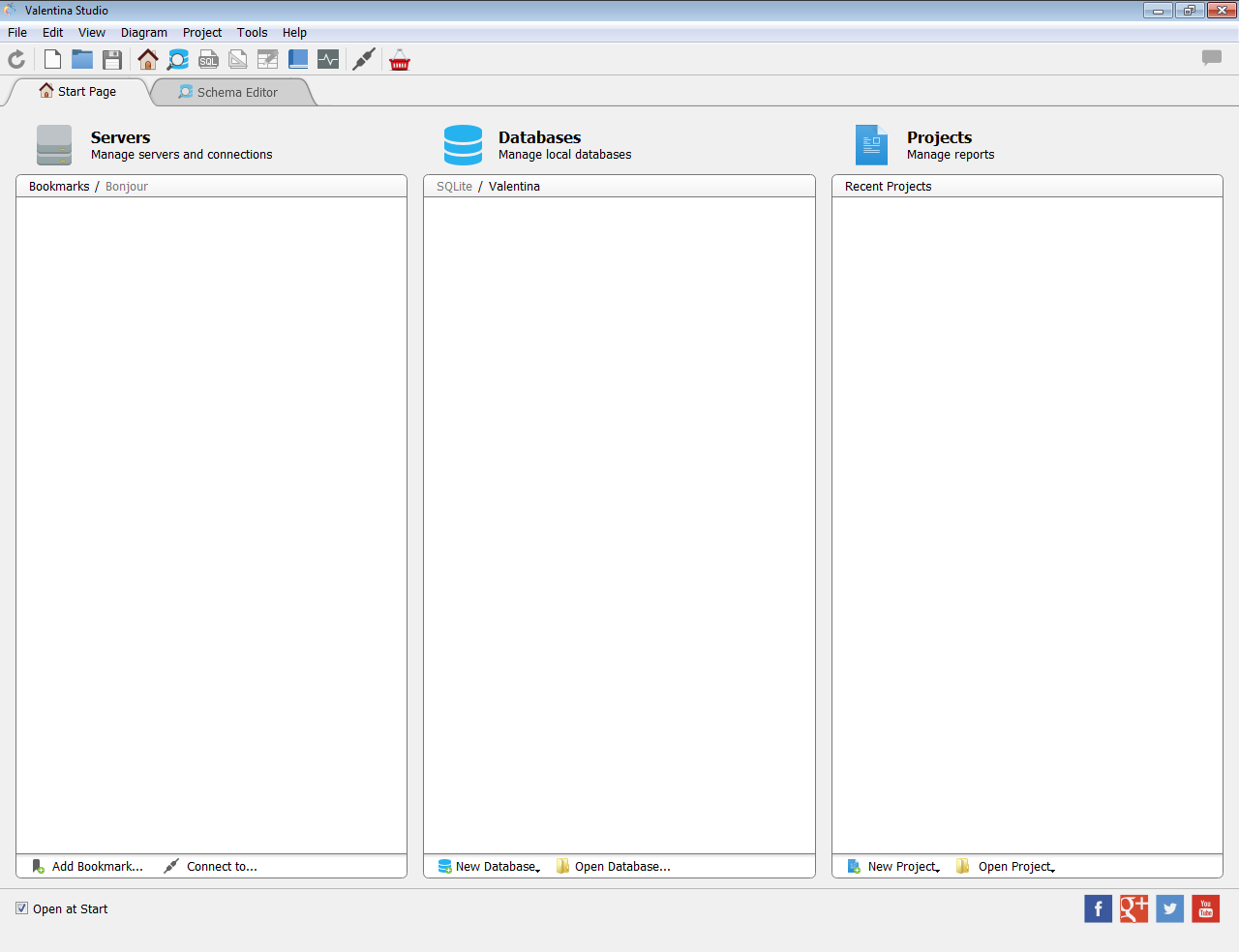
選右上角的File -> Connect to…以後會有這樣的一個表格,跟下圖的內容填就好了。密碼跟帳號同樣是steemit。
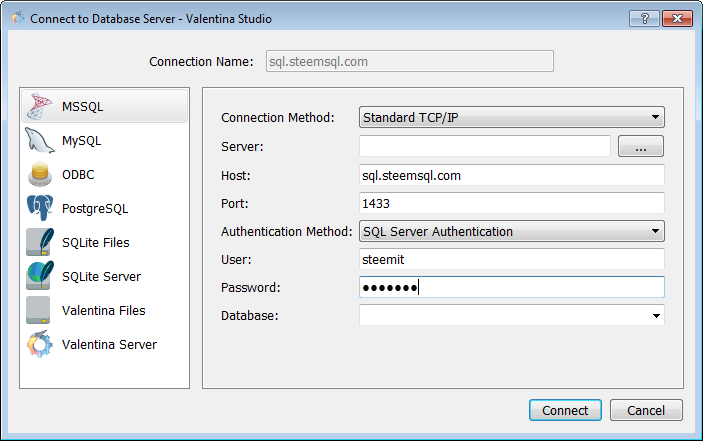
輸入以後按Connect,就會有以下的介面。
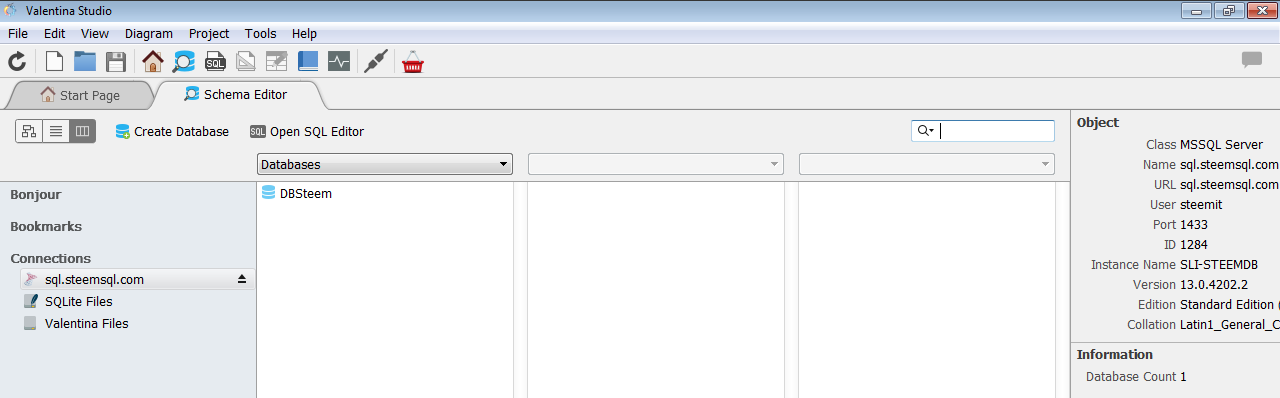
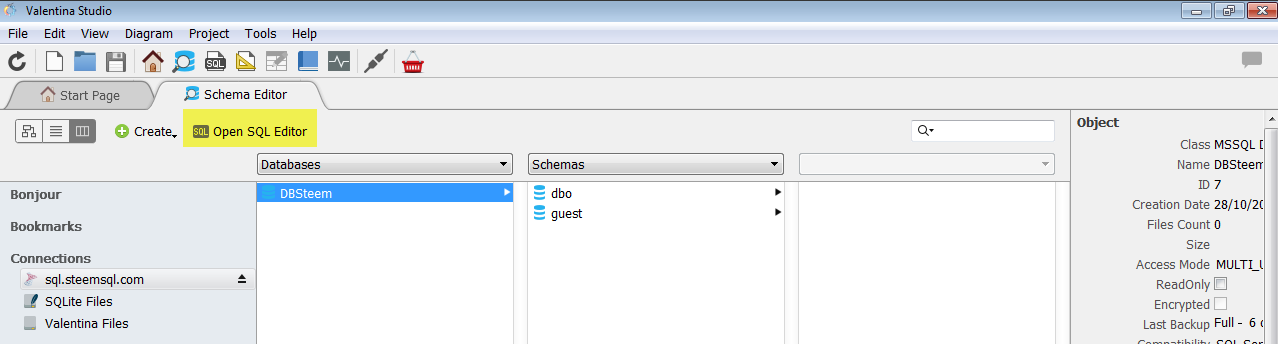
按一下DBSteem,再按Open,你應該就能看到dbo底下有很多個數據表:

用SQL查詢數據庫
接下來就要用SQL來提數了,選了DBSteem以後按Open SQL Editor。
最簡單的你可以用以下的code去看一下一個table的結構跟內容:
SELECT TOP (n) * FROM (table name);
要去理解這句code,就是著它從(table name) [FROM (table name)] 選取 [SELECT] 首n條 [TOP (n)] 記錄的所有字段[*]。 (記得要限制結果數量,不然的話整個數據表的資料都顯示出來要花很長時間)
比如我寫
SELECT TOP 10 * FROM Txcomments;
就是從Txcomments這個數據表拿首十條記錄的所有字段出來看。按一下左上方的Execute結果就出來了。
來看看跑出來的結果:
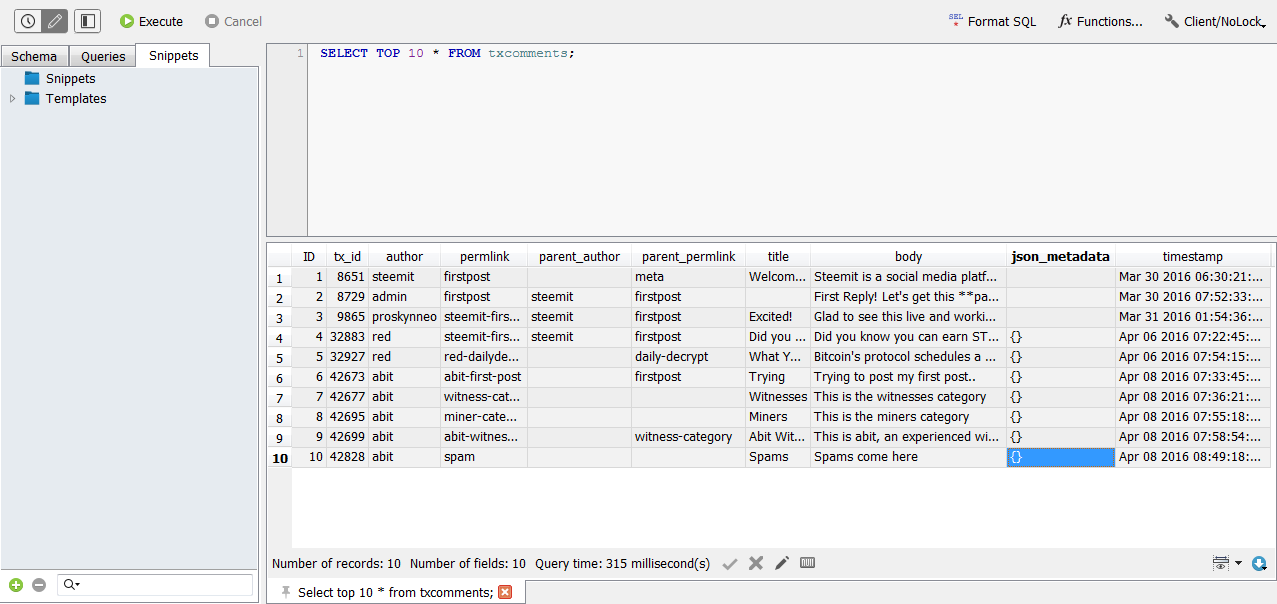
這樣你就能看出來Txcomments是載著每一個帖子或留言的資料,且分別存在什麼字段。所以大家可以試試探索一下不同的數據表都在載什麼東西~
要是我想找一下 @cnfund最新出的十章小說,且只需要作者名、文章標題、內容跟發表時間,就會用以下的SQL code:
SELECT TOP 10 author, title, body, timestamp //選出首十條記錄的作者、標題、內容跟時間
FROM Txcomments //從Txcomments中提取
WHERE author = 'cnfund' and title <> '' //作者需要是cnfund且標題不能為空(即只要帖子、不要留言)
ORDER BY timestamp DESC; //以時間倒序排列
結果如下:
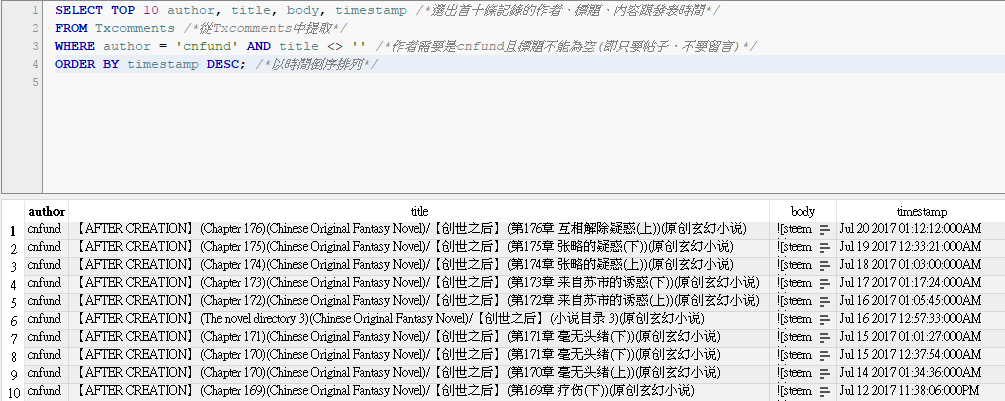
其實SQL code是很好理解的,有不知道應該怎麼寫的時候google一下就很容易能找到答案。
最後還可以把結果導出。結果的右下角選Export Result就可以了。
如果要做簡單的分析,可以把結果導出到Excel,相信大家應該對Excel都有一定程度的熟識
另外,測試過Steemsql的數據大概只有延遲3分鐘左右,這方面比SteemData好,而且SQL應該比Python要易上手吧 (但還是鼓勵大家學一下Python,真的很有用,而且學了以後比較能看懂o哥的技術文 XD)。
今天就先介紹這些吧~ 謝謝收看
參考資料
如果你喜歡我的文章,歡迎follow @rayccy! :)