之前用两篇文章复习了字符串编码的相关知识并做了一些验证。但是我们学习知识的目的是为了更好地使用,否则除了占用脑细胞就没啥其它意义了(好像占不到我的脑细胞,因为我会很快地忘掉)。

(图源 :pixabay)
因为有不同编码的存在,所以在编程解决问题的过程中难免会遇到编码转换的问题。比如说我的程序设置使用Unicode编码,但是程序中读取到一段文字却使用了GB2312编码,然后我们要将这段文字POST给某个网页处理,这时候又要使用UTF-8编码,这真是让人头晕甚至头大的问题。
幸好,微软给我们提供了很多函数,让我们可以很方便的处理诸如此类的转换。最常见的函数莫过于WideCharToMultiByte以及MultiByteToWideChar两个函数,前者将宽字节字符串转换成多字节字符串,后者做相反的工作。
WideCharToMultiByte
以WideCharToMultiByte为例,它的语法(函数声明)如下:
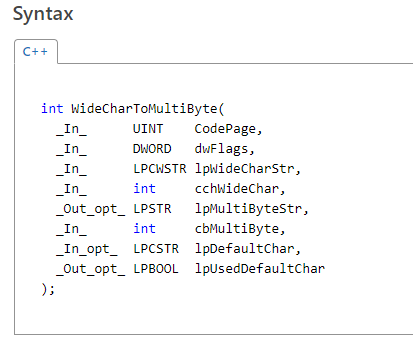
咔咔,是不是头更大了?其实也没多复杂,有关参数的说明,参考此处即可(良心呢?良心疼不疼?)
但是有一个要注意的问题,_Out_opt_ LPSTR lpMultiByteStr,这个参数用于接收转后的字符串,但是很多时候我们很难预估转换后的字符串会占用多少字节,这时候定义一个固定长的buf,或者使用内存分配函数分配固定长度的内存空间,都是不适当的。
一般的做法是先调用一遍WideCharToMultiByte这函数,但是把输出字符的指针以及输出字串的长度分别设置为NULL和0,这样调用会返回目标字串的长度。我们根据这个返回的长度分配内存,然后再次调用转换函数就会得到目标字串。需要注意的使用完目标字串后,要记得释放内存。
MultiByteToWideChar这个函数的用法和需要注意的内容与WideCharToMultiByte大同小异,就不额外介绍了。
CW2A & CA2W
尽管WideCharToMultiByte与MultiByteToWideChar 可以很好地处理不同编码之间的字符串转换,但是用起来还是非常麻烦的。先要调用一遍来测试目标串长度,然后再分配内存,再调用函数进行转换,用完还是记得释放内存,更不用说还有一堆参数要填。
CW2A & CA2W的出现彻底将我们从这些繁重的劳动中解放出来。
你可能很好奇,它是怎么实现的呢?答案是,尽管CW2A & CA2W看起来很简单,实际上它内部去做上述繁复的工作😵。
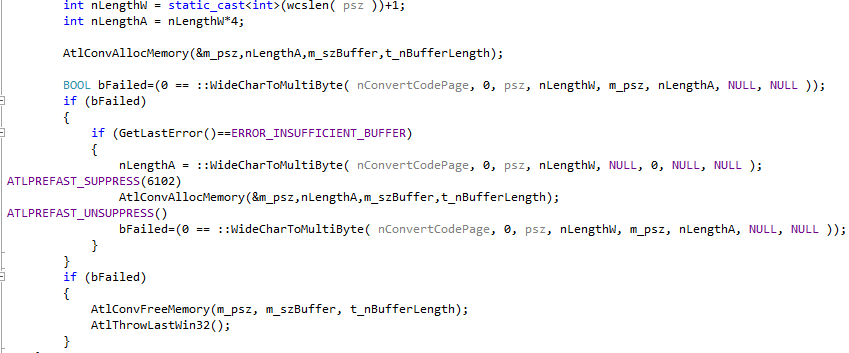
以上是CW2AEX类的部分代码,可见它也是使用了WideCharToMultiByte这个函数。
另外代码中,AtlConvAllocMemory(&m_psz,nLengthA,m_szBuffer,t_nBufferLength);这个函数很有意思。结合CW2AEX类,大致思路是提供一个字节数组,如果目标字串的长度大于字节数组的长度,那么重新分配内存,否则使用这个字节数组作为接收区。
CW2A & CA2W 作用域
因为在CW2AEX类的析构函数中会释放内存,所以使用CW2A & CA2W 等函数时要注意作用域的问题。假设我们用类似:LPTSTR p = CA2W(str1);来保存结果,那么再次使用p的时候,因为p对应的内存已经被释放,所以可能得到一些垃圾数据或者意想不到的结果。这里就不再赘述了。