
Introduction
Without going into my life story, SEO (Search Engine Optimisation) has always been of interest to me both professionally and whatever the non-professional equivalent is. I find the idea of getting a particular search term to the top of Google's rankings interesting and in my younger days, created various websites with attaining a high Google ranking as its sole purpose (without resorting to the darker-habits of hidden content for example). Many of these experiments went better than expected.
Whereas Google's rankings have always been a bit of a dark art, requiring a combination of technical skills (the ability to write good code) and copywriting skills (the ability to choose the best key words to target the masses or long tail), the complexity of the ranking system has increased as the years have passed, taking into account variables such as location, device, inbound links and where they're coming from.
I'm digressing slightly from the point of my post which isn't supposed to be a background to SEO. Instead, it's an experiment I ran on steemit.com to see if an unintended consequence of content being posted within communities is that we are damaging the ranking (and therefore visibility) of our content on Google.

How Do Communities Affect SEO?
One thing that Google has always ranked is the URL of a site's content. With the domain name having importance, the section having importance and the page URL having importance. So if you have 2 pages on the same site and one has the URL:
@elephant-man/why-i-love-jumbo-elephants
and the same content posted under the URL:
@tiger-lover/why-i-love-jumbo-elephants
A search for "Jumbo Elephants" would favour the first URL.
And this concept is the basis of my experiment.

Hypothesis
Posting within a community has a detrimental affect upon your content's Google Ranking compared to a targeted username using an appropriate primary hashtag.

Method
I would use my existing @sporting-gorilla account to write some predicted lineups for last night's match between Real Madrid and Chelsea. The post would be written with specific keywords in mind.
A new account (@predictedlineups) would create a post with the identical content - identical title, identical content and identical hashtags.
@sporting-gorilla's post - @sporting-gorilla/real-madrid-v-chelsea-predicted-lineups
@predictedlineup's post - @predictedlineups/real-madrid-v-chelsea-predicted-lineups
The posts would be made at the same time on Thursday 7th April, 5 days before the match kicked off and for a site of steemit.com's content fluidity, enough time to get picked up and indexed by Google.
The page title ("Real Madrid v. Chelsea Predicted Lineups") is the initial search term to be analysed and if successful, quotes and other words could be removed and experimented with.
Within the posts, the number of variables have been kept to an absolute minimum - focussing on the URL as the key element to be tested. Potential variables that cannot be controlled are user comments, user votes and the posts' position in the "Trending" page.
Results
Searching for the term "Real Madrid v. Chelsea Predicted Lineups" returned no results until day 6 (today) with 3 results now being returned:
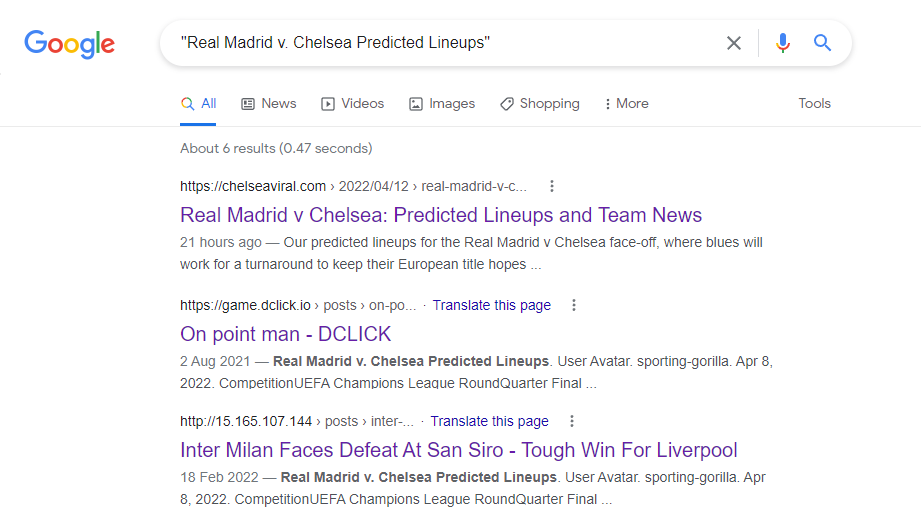
- https://chelseaviral.com/2022/04/12/real-madrid-v-chelsea-predicted-lineups-and-team-news/
- https://game.dclick.io/posts/@harddrive/on-point-man
- http://15.165.107.144/posts/@dimple-gh/inter-milan-faces-defeat-at-san-siro-tough-win-for-liverpool
Results 2 and 3 are where the post appears in the "Related" section of another user's older article.
Only result 1 was published within the past 2 months.
If we search specifically for the site steemit.com, we are returned the following:
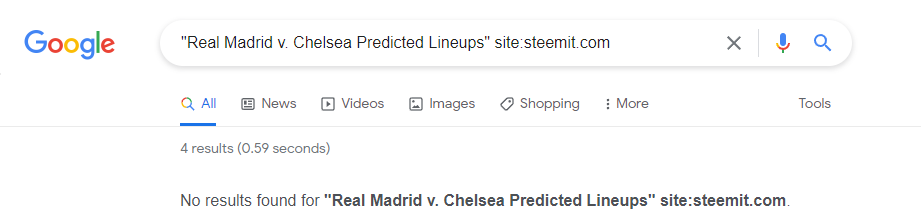
So despite the article being written 5 days before the match and the match now having been completed (and therefore the article is somewhat irrelevant), Google has still not indexed the article.
Conclusion
It is not possible to make any conclusions based upon the initial hypothesis until either page has been indexed. Therefore, I will continue to monitor this search term until this happens and update you if/when the time comes.

Closing Thoughts
I'm very surprised by my findings. I expected a site of steemit.com's nature to get crawled regularly and for much more of the content to get indexed. This lack of indexing perhaps explains why many of the articles that appear in Google's search results are 4 or more years old.
There are many things that could contribute to the lack of indexing. Putting steemit.com into this Google simulator shows what Google's web crawler sees. I've not spent much time analysing the results but I can instantly see that if a user's deterred by Steemit's home page, we're lucky compared to what Googlebot is seeing.
It's also interesting that the "Related" section of game.dclick.io is indexed before steemit.com's original articles are. It has crossed my mind that Google has penalised the steemit.com domain name but my understanding is that the consequence is a lower ranking, rather than not getting indexed.
It's also possible that the crawler is indexing the content on the site that it can find but it simply can't find my articles. Without access to Steemit's Google Search Console, I have no way of knowing.
I have many more thoughts on this topic and will no doubt share some of these with you in the future. For the time being though, I hope you enjoyed my little experiment and as always, I look forward to hearing your thoughts.
