
- 데이터 마이닝과 인공지능을 공부하다보면, 같은 교사(Supervised) 및 비교사(Unsupervised) 학습 알고리즘을 통해 접근하는 것을 볼 수 있습니다. 분명히 데이터 마이닝, 인공지능이라는 분야를 나눈 이유가 있을 텐데 과연 무엇일까요?
1 . 데이터 마이닝 (Data Mining)
1) 목적
- 데이터 마이닝의 목적은 새로운 규칙, 주 속성 탐색이 목적입니다. 데이터 마이닝 이름에 걸맞게 수많은 데이터 중 금이 될 데이터를 찾는 것입니다.
- 많은 데이터 들의 유용한 상관관계를 찾아내며, 통계적 기법을 통해 적용합니다. 따라서 데이터가 어떻게 도출 되었는지에 대한 과정도 중요합니다.
2) 과정
- 데이터 마이닝 기법의 표준은 CRISP-DM (Cross-Industry Standard Process - Data Mining) 으로 CRISP-DM의 절차는 아래 그림과 같습니다.
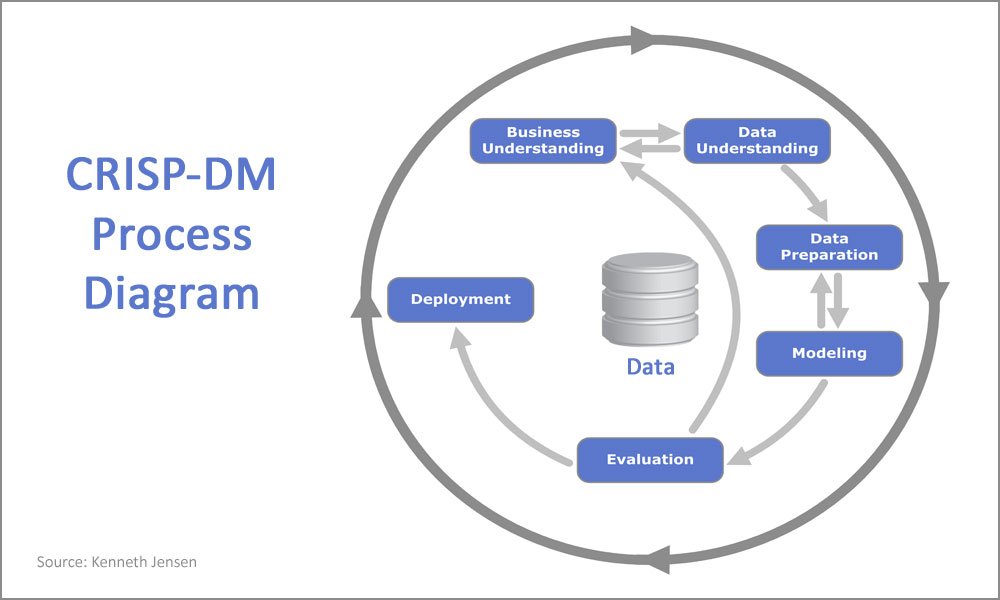
- CRISP-DM 의 과정은 아래와 같습니다.
(1) 사업 이슈 이해 (Business Issue Understanding)
- 적용할 프로젝트에서 발생하는 문제점을 파악하고, 프로젝트의 특성을 파악합니다.
(2) 데이터 이해 (Data Understanding)
- 모델을 만들기 전에 데이터의 특성을 파악합니다. 또한, 데이터가 어떻게 생성 되었는지 파악합니다.
(3) 데이터 준비 & 전처리 (Data Preparation)
- 모델을 만들기 전에 데이터가 누락되어있는지 않았는지, 오탈자가 있는지 확인합니다. 또한, 데이터를 정규화(Nomalization) 하여 데이터 마이닝 적용을 용이하게 합니다.
(4) 분석 & 모델링 (Analysis/Modeling)
- 데이터를 분석한 토대로 어떠한 알고리즘을 적용할지 분석하고 적용합니다.
(5) 검증 & 평가 (Validation/Evaluation)
- 적용한 결과를 검증하고 정확도 등을 평가합니다. 이 과정에서 검증과 평가치가 부족하다면 적절한 알고리즘을 적용하지 못했거나, 데이터의 전처리가 잘못 된 것일 수 있습니다.
(6) 발표 & 시각화 (배포) (Presentation/Visualization (Deployment))
- 적용한 모델의 검증과 평가가 완료되고 만족하다면 다른 사용자들이 활용할 수 있게 배포합니다.
2 . 인공지능 (Artificial Intelligence)
1) 목적
- 인공지능은 새로운 규칙과 주 속성 발견 보다, 데이터를 기반으로 추후에 들어오는 데이터에 따라 어떠한 결과를 예측을 하느냐가 중요합니다.
- 반복학습을 통해 알아가는 과정으로, 어떻게 풀었는지에 관해 알기보다 빠른 결과와 정확한 결과가 중요합니다.
- 예측 모델의 일반화가 중요하며, 데이터 특성을 너무 따라가 생기는 과적합(Overfitting)을 피하는게 목적입니다.
2) 과정
- 인공지능의 과정은 데이터 마이닝과 유사한 점이 있으나, 예측 모델의 일반화를 위해 평가 & 검증 하는 방식이 다르다.
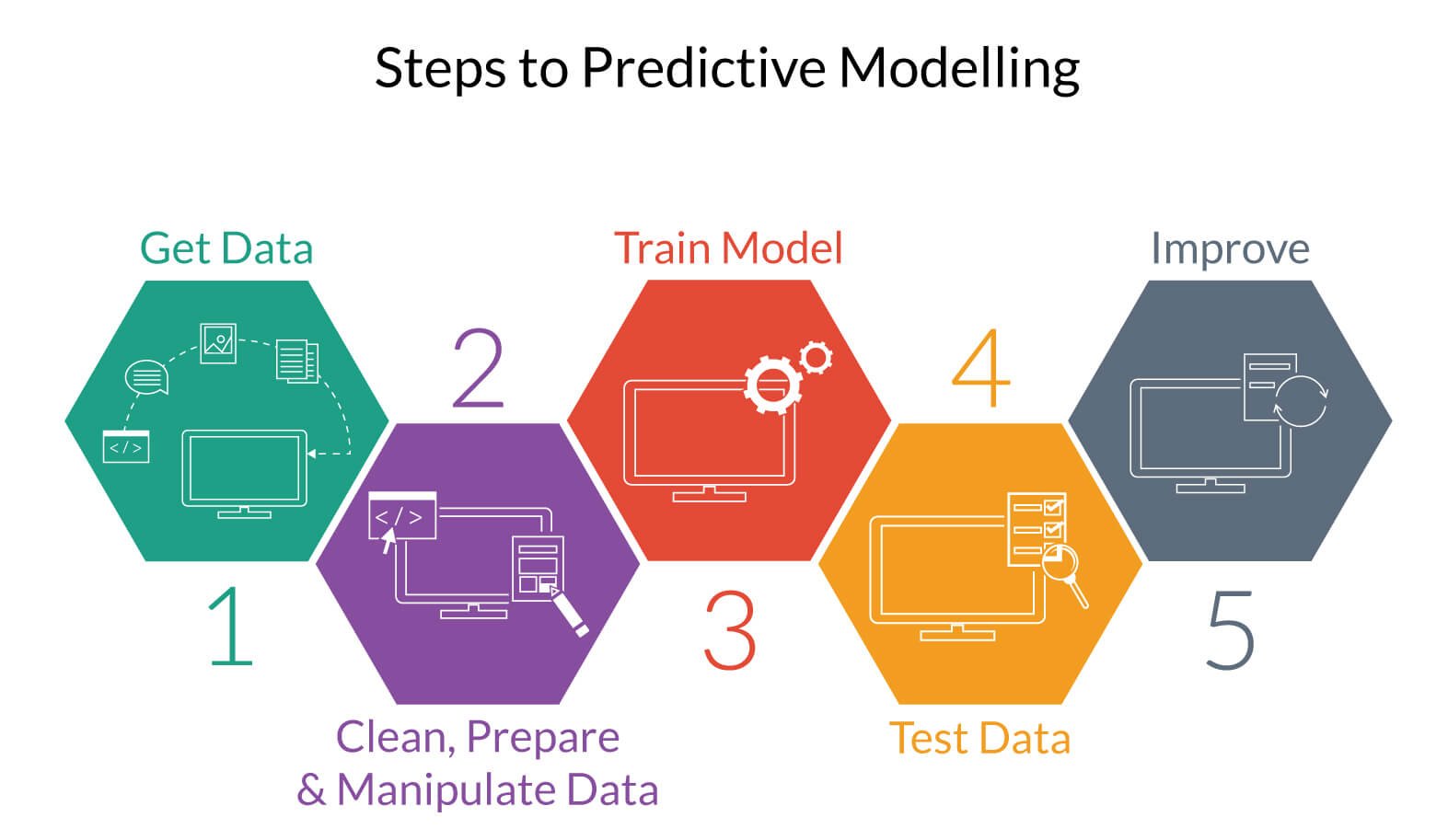
(1) 데이터 확보 (Get Data)
- 인공지능을 적용할 데이터를 얻습니다. 그 과정에서 전문가의 의견을 통해 속성의 특성에 관해 조언을 듣는 것이 중요합니다.
(2) 데이터 전처리 (Data Preparation)
- 앞서 말한 데이터 마이닝과 같이 모델을 만들기 전에 데이터가 누락되어있는지 않았는지, 오탈자가 있는지 확인합니다. 또한, 데이터를 정규화(Nomalization) 하여 예측 모델 개발을 용이하게 합니다.
(3) 피처 선택 (Feature Selection)
- 변수 선택이라고도 하며, 예측에 용이한 데이터를 선정합니다. 피처 선택에 따라 예측 모델 개발을 위한 시간이 길어질 수도 짧아질 수 도 있습니다. 이는 모델 개발을 맡는 전문가의 경험이 중요합니다.
(4) 알고리즘 선정 (Alogorithm Selection)
- 선정한 변수의 특성에 맞는 알고리즘을 선정합니다. 라벨이 있을 경우 교사학습 (Supervised Learning), 라벨이 없는 경우 비교사학습(Unsupervised Learning)을 적용합니다.
(5) 예측 모델 학습 (Train Model)
- 알고리즘을 선정하였다면, 예측 모델을 학습 시킵니다. 검증 & 평가의 과적합을 피하기 위해 데이터의 70%만 담아 예측 모델을 학습시킵니다.
(6) 모델 검증 및 평가 (Model Validation & Evaluation)
- 나머지 데이터 30%를 적용하여 예측된 값과 평가된 값을 확인합니다. 데이터 마이닝과 마찬가지로 이 과정에서 검증과 평가치가 부족하다면 적절한 알고리즘을 적용하지 못했거나, 데이터의 전처리가 잘못 된 것일 수 있습니다. 3번의 피쳐 선택 과정으로 돌아가 알맞게 다시 적용하도록 합니다.
(7) 배포 (Deployment)
- 예측 모델이 검증 및 평가의 값이 만족스럽다면, 사용자들이 사용할 수 있게 배포합니다.
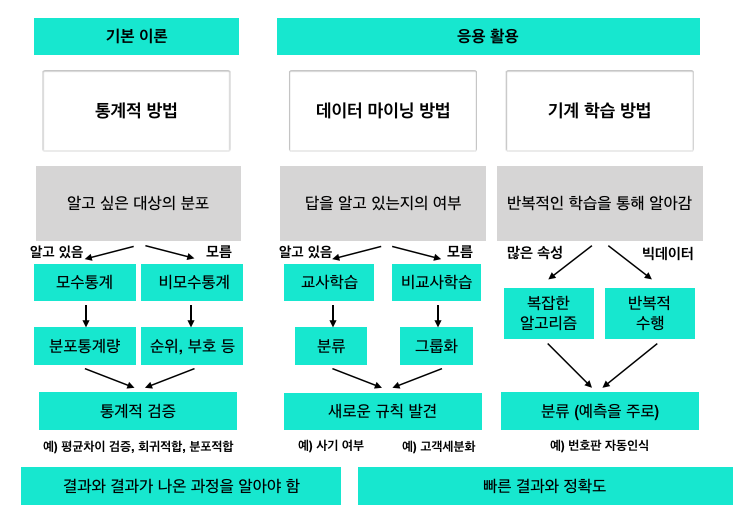
3 . 데이터 마이닝과 인공지능의 방법론
- 데이터 마이닝과 인공지능의 방법론은 아래의 그림을 통해 알 수 있습니다.
4 . 마치면서
- 데이터 마이닝의 목적과 과정을 알아보았습니다.
- 인공지능의 목적과 과정을 알아보았습니다.
- 데이터 마이닝과 인공지능의 방법론을 알아보았습니다.
- 다음 장에는 인공지능의 역사를 알아보도록 하겠습니다.
5 . 참고문헌
1 . http://www.stellarconsulting.co.nz/blog/data/crisp-dm-still-a-leader/
2 . https://upxacademy.com/introduction-machine-learning/
3 . DS Trade, "Microsoft 고급분석도구 교육 Microsoft Analytics Tool & Service", 2017.11
4 . https://docs.microsoft.com/ko-kr/azure/machine-learning/team-data-science-process/
5 . IBM 비즈니스 가치 연구소, "분석 : 빅데이터의 현실적인 활용 혁신 기업이 불확실한 데이터에서 가치를 창출해 내는 방법", 2012.10
6 . https://docs.microsoft.com/ko-kr/azure/machine-learning/preview/
7 . 김의중, "알고리즘으로 배우는 인공지능, 머신러닝, 딥러닝 입문", (위키북스) 2016.07
1. 인공지능의 정의와 종류
2. 인공지능의 트랜드와 시장
저에 대해 궁금하신 점이 있으시면 아래 자개소개 글 보러가기 링크를 통해
자개소개 글을 봐주시면 감사하겠습니다 ^^ /