
인공지능 관련 포스팅을 위해 알파고에 대해 좀 더 자세히 공부하면서 생각이 좀 많이 달라졌다. 2016년 3월 이세돌을 4:1로 누른 '알파고 리'는 1202개의 CPU와 176개의 GPU로 구성된 막강한 계산능력을 갖춘 인공지능이었다. 존경하는 도올 샘께서도 이 대국을 두고 "인간이 계산기를 이길 수 있겠느냐"며 대결의 부당성마저 제기하였다. 필자 또한 반은 그렇게 생각했다. 그러나...
작년 3월 세계 최정상 프로기사를 처음으로 누른 '알파고 리'에서 시작하여 올해 5월말 바둑 세계 랭킹 1위인 커제를 3:0으로 가뿐하게 누른 '알파고 마스터' 그리고 이 '알파고 마스터'를 100:0으로 완패시킨 '알파고 제로'!
알파고는 이렇게 엄청난 속도로 진화하면서 단순한 계산 능력이 아닌 인간의 사고를 흉내내는 알고리즘의 발전으로 이어지고 있는 것을 보고 생각이 바뀌지 않을 수 없었다.
자~ 그럼 알파고는 어떻게 정의되는 것일까?
몬테 카를로 검색 방식을 적용하여 13층의 컨벌루션 신경망으로 지도학습과 강화학습을 통해 만들어진 가치망과 정책망으로이루어진 바둑 전용 인공지능이다.
무슨 말인지 하나도 모르겠다!!!
사실 신경회로망을 주제로 석사학위를 받은 필자도 한번에 이해가 안되는데 비전공자들이 이것을 이해하기란 쉽지 않을 것이다. 하지만 가능한한 이해하려고 노력해보자. 인공지능이 미래의 트렌드임이 확실한데 나만 무식하게 살 수는 없지 않은가? ㅎㅎ
몬테 카를로 검색(MCTS, Monte Carlo Tree Search)
몬테카를로(프랑스어: Monte-Carlo, 모나코어: Monte-Carlu, 오크어: Montcarles)는 모나코를 구성하는 10개 행정구 가운데 하나이다.[1] 종종 모나코의 수도로 오해되기도 하나 이는 사실이 아니며, 도시 국가인 모나코의 수도는 모나코 영토 전체이다. 지중해 연안의 리비에라 해안에 위치하고 있는 몬테카를로는 프랑스가 그 주변을 둘러싸고 있으며, 이탈리아와도 매우 가깝다.거주 인구는 약 3,000명이다. 카지노와 도박장으로 유명하다. from 위키피디아
카지노로 유명한 모나코의 도시의 이름을 딴거 보면 이것은 무작위 선택(random choice)를 썼다는 것이다. 도박도 확률 게임이기는 하지만 수학 계산과는 달리 인간의 감(hunch), 즉 통박이 주요한 선택 방법이기 때문에 검색 알고리즘의 이름을 이렇게 붙인 것이다.
바둑은 그 경우의 수가 우주에 존재하는 원자의 갯수를 다 합한 것보다 많다고 하니 단순히 모든 경우의 수를 다 검색 판단하는 것(이것을 brute-force 방식이라고 한다)은 불가능하다. 따라서 알파고가 다음 수를 둘 때는 이러한 인간의 통박과 비슷한 알고리즘을 사용한다는 것이다. 사실 이것이 난공불락이라고 여겨지던 바둑의 세계를 인공지능이 접수하게된 가장 중요한 열쇠가 된다.

위의 그림처럼 몬테 카를로 검색 방식을 적용하게 되면 가지마다 깊이가 다르게 된다. 즉 가치가 있는 판단에 대해서만 깊이 생각하는 것이다. 인간과 동일하지 않은가?
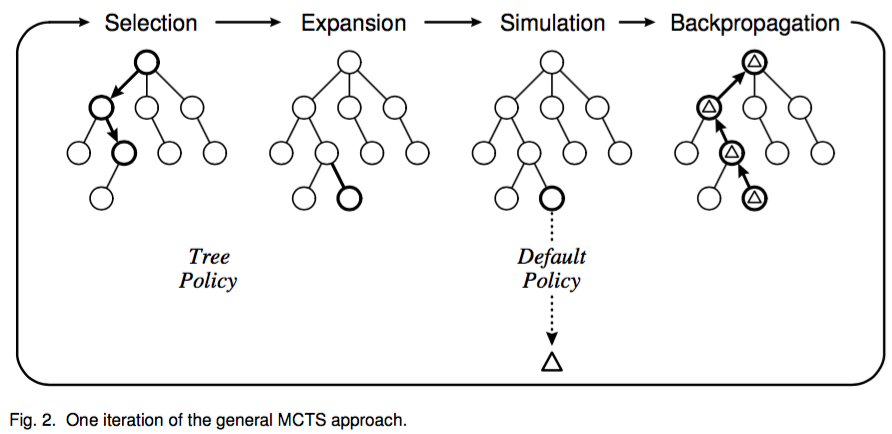
알파고는 이러한 몬테 카를로 검색 방식을 적용해서 선택 -> 확장 -> 시뮬레이션 -> 역전파 과정을 계속 반복하여 이길 수 있는 수를 찾아낸다.
컨벌루션 신경망(CNN, Convolution Neural Network)
Time domain에서 두 함수를 컨벌루션하면 Frequency domain에서는 두 함수를 곱한 것과 같다.
f(t) = g(t) * h(t) => F(s) = G(s) x H(s)
대문자와 소문자는 라플라스 변환 관계
여기서 * 는 컨벌루션 연산을 의미하고 x 는 곱하기 연산.
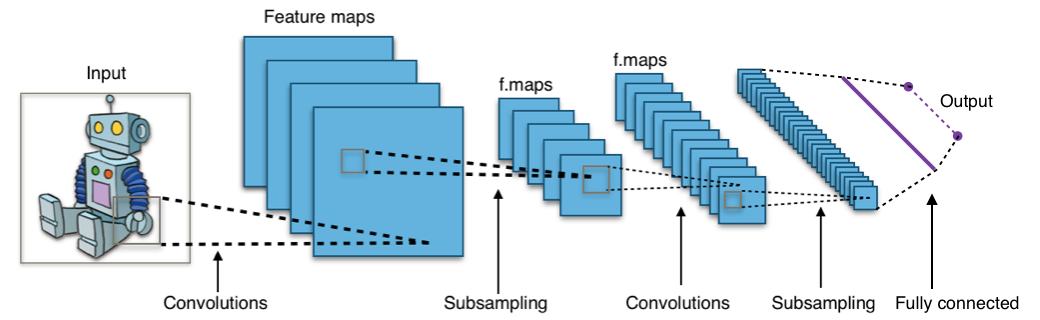
그런데 여기서 말하는 컨벌루션 연산은 쉽게 말해서 이미지 필터링이다. 이렇게 이미지 필터를 적용하는 이유는 말할 것도 없이 인공지능 즉 컴퓨터가 계산하기 쉽게 만들어주기 위한 것이다.

인간은 왼쪽 사진을 보고 개와 배경을 쉽게 구분하지만 컴퓨터는 에지 필터(여기서는 Edge filter를 컨볼루션했다)를 이용하여 윤곽을 분리한 뒤 개인지 아닌지를 구분하는 것이다.
그렇다면 알파고에 왜 이미지 필터를 적용하는 것일까?
그렇다! 알파고는 돌이 놓여진 바둑판을 이미지로 인식하고 처리하는 것이다.
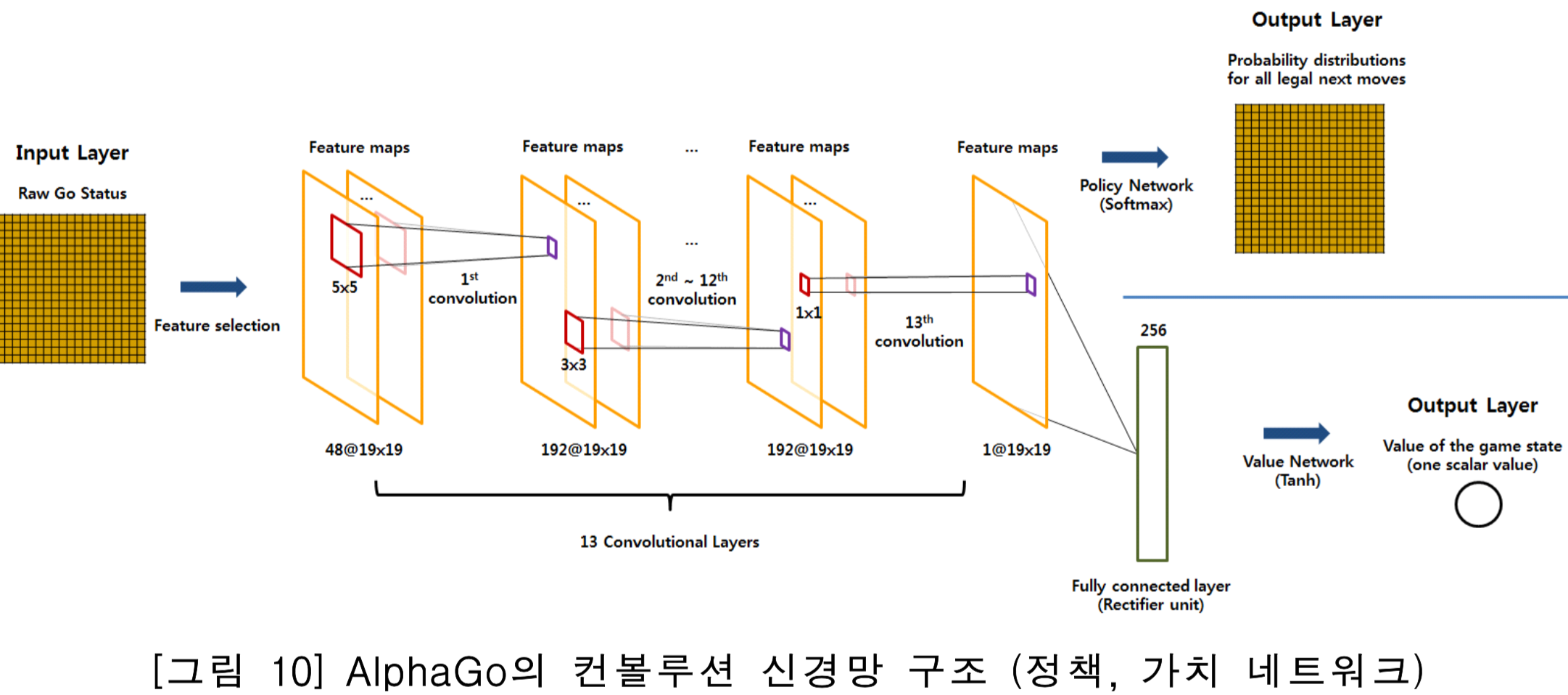
위의 그림 중간에 보여진 convolution layer가 모두 13개이고 그래서 D.E.E.P.~ 하다는 것이고 이를 Deep Learning이라고 부른다.
지도학습(SL, Supervised Learning)과 강화학습(RL, Reinforcement Learning)
알파고는 수천만가지의 기보를 익혔다고 전해진다. 이렇게 기존 기보를 가지고 프로기사들이 두는 다음 수를 모두 classification 하는 방법으로 학습시키는 것을 지도학습이라고 한다.
하지만 지도학습만 가지고 반드시 승리한다는 보장이 없고 또 바둑이 진행될수록 같은 수를 놓은 경우가 적어지기 때문에 스스로 바둑을 진행하면서 수를 익히는 자가 학습법인 강화학습을 통해서 승률을 올린다. '알파고 제로' 버전이 놀라운 것은 바둑의 규칙만 알려주고 오로지 강화학습을 통해서 기력을 올렸다는 점이다. 이런 이유로 알파고가 수많은 기보를 익혔기 때문에 최정상의 프로기사를 이겼다는 해석은 설득력이 없다.
정책망(Policy Network)과 가치망(Value Network)
정책망은 주어진 현재 상태를 고려하여 다음 수를 결정하는 데 있어서 확률분포를 적용한 개념이다. 이건 또 뭔 소리여???
최대한 쉽게 설명하자면 같은 입력에 대해 다른 출력(결과물)이 나올 수 있다는 것이다. 엑셀에 수식을 만들면 어떤 경우라도 같은 입력에 대해선 같은 출력이 나와야한다. 하지만 몬테 카를로 검색 방식에서는 다른 결과가 나올 수 있다는 것이다. 앞서 언급하였듯이 이러한 선택 방법이 알파고를 인간과 보다 가깝게 만들어준 중요한 열쇠이다.
정책망과는 달리 가치망은 이 수를 통해서 얻어지는 승패의 결과를 알려준다. 가치망의 결과값은 Win or Lose이다. 알파고는 가치망을 통해 승패를 판단하는데 현재판에서 둘 수 있는 어떠한 수를 두어도 가치망의 결과값이 Lose가 나오면 주저없이 돌을 던진다.

"AlphaGo resigns"
이세돌이 알파고와의 4번째 대국에서 통쾌한 승리를 거두었던 역사적 장면이다. 필자는 당시 5국 전체를 실시간으로 시청하였는데 이 4번째 대국이 인간이 인공지능을 상대로 이겼던 마지막 대국이 될 것이라는 것을 직감하였고 슬프게도 그것이 실제로 현실이 되고 있다.
PS : 이번 포스팅은 좀 힘든 작업이었습니다. 솔직히 100% 이해하지 못하는 주제에 대해 비전공자들이 이해하기 쉽게 쓴다는 것이 몹시 어려웠습니다. 혹시 제가 언급한 내용 중에 틀린 내용이 있으면 가차없이 댓글 달아주시기 바랍니다. 정확하게 오류를 지적해 주시면 기쁜 마음으로 풀 보우팅 해드리겠습니다.
그리고 알파고에 대해 제가 올린 것보다 더 재미있고 이해하기 쉽도록 포스팅해 주시면 풀 보우팅은 물론이고 상금으로 50 SBD를 송금해드리겠습니다. ㅎㅎㅎ