
안녕하세요. 어미새입니다.
이전 포스팅에서 합의 문제, 합의 알고리즘에 대해서 알아봤습니다.
블록체인에서 합의 알고리즘이란 어떤 방식으로 블록을 생성해 낼 것이며, 어떤 블록이 '진짜'인지 판별하기 위한 알고리즘이라고 설명해드렸습니다.
좀 더 구체적으로 설명을 해드리자면 블록체인을 조작할 수 없어야 하고어떤 블록이 유효한지 확인할 수 있는 메커니즘이 필요합니다. 이러한 과정을 검증하는 메커니즘이 합의 프로토콜, 합의 알고리즘이라고 생각하시면 됩니다. 또한 합의 알고리즘은두 개의 유효한 블록체인이 생성됐을 때 하나를 선택하는 방법도 필요합니다.
혹시 못 보신 분은 먼저 합의문제 합의 알고리즘에 대해 읽어보시면 좋을 것 같습니다.
(@yahweh87/1-consensus-problem)
이번 포스팅에서는 '해시함수'란 무엇이고 블록체인에서 '해시함수'는 어떤 역할을 수행하는지에 대해 알아보도록 하겠습니다.
'해시함수'의 특징 및 역할은 추후 블록 구성요소에 대해 학습하기 위해서 반드시 개념을 알고 넘어가야합니다.
해시 함수란 무엇인가?
해시 함수는 임이의 길이를 갖는 메시지를 입력받아 고정된 길이의 해시값을 출력하는 함수입니다. 암호 알고리즘에는 키가 사용되지만, 해시 함수는 키를 사용하지 않으므로 같은 입력에 대해서는 항상 같은 출력이 나오게 됩니다. 이러한 해시함수를 사용하는 목적은 메시지의 오류나 변조를 탐지할 수 있는 무결성을 제공하기 위해 사용됩니다.
(https://seed.kisa.or.kr/iwt/ko/intro/EgovHashFunction.do)
해시 함수의 특징
- 어떤 입력 값에도 항상 고정된 길이의 해시값을 출력한다.
- 눈사태 효과 : 입력 값의 아주 일부만 변경되어도 전혀 다른 결과 값을 출력한다.
- 출력된 결과 값을 토대로 입력값을 유추할 수 없다.
SHA(Secure Hash Algorithm)
해시(Hash)의 종류에는 MD 알고리즘 및 SHA 알고리즘이 있습니다. 이번 포스팅에서는 비트코인에서 사용되는 알고리즘인 SHA256 함수에 대해서 알아보도록 하겠습니다.
SHA(Secure Hash Algorithm)알고리즘은 미국 NSA에 의해 만들어졌습니다. 160비트의 값을 생성하는 해시 함수로, MD4가 발전한 형태입니다. MD5보다 조금 느리지만 좀 더 안전한 것으로 알려져 있으며, SHA에 입력하는 데이터는 512비트 크기의 블록이며 알고리즘의 동작원리는 아래 그림과 같습니다.
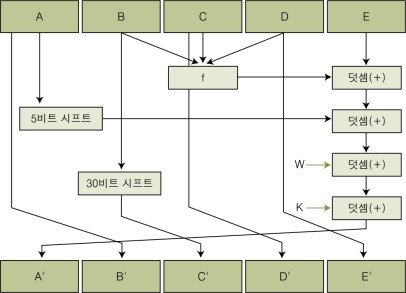
SHA 알고리즘은 크게 SHA-1과 SHA-2로 나눌 수 있으며 종류에 따른 성능은 아래의 표와 같습니다.

간략하게 해시함수의 역할 및 특징 그리고 종류에 대해서 알아봤습니다.
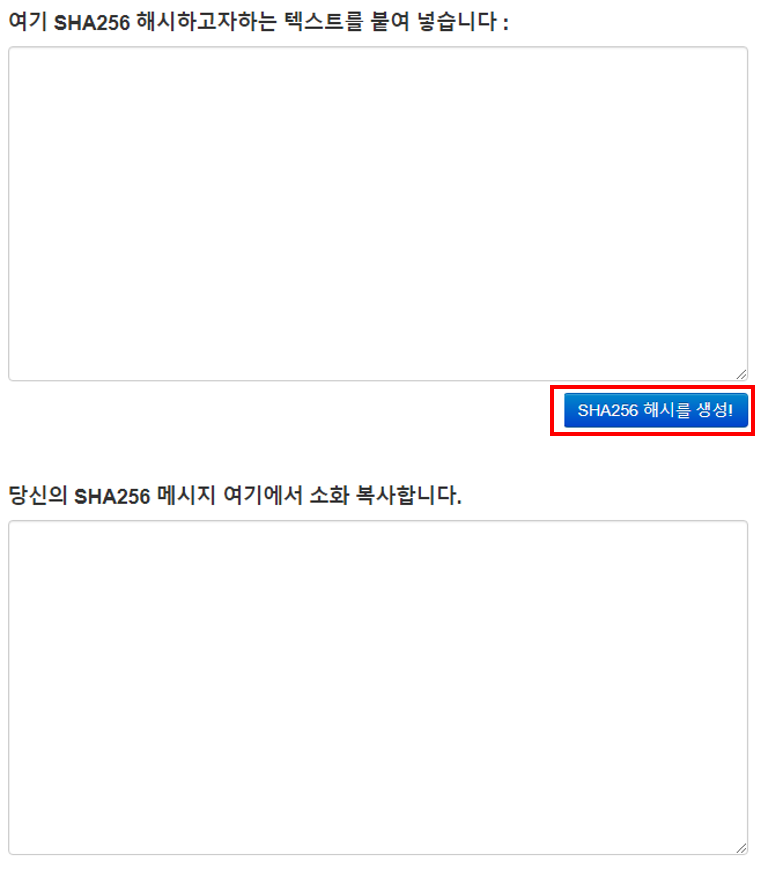
아래의 사이트는 입력 값을 SHA256 방식으로 변환해주는 사이트입니다.
(http://www.convertstring.com/ko/Hash/SHA256)
사이트에 나와 있는 것 처럼 상단의 입력박스에 해시하고자하는 입력 값을 누른 후 파란색 버튼인 'SHA256 해시를 생성!' 버튼을 누르면 해시 값이 출력됩니다.
자 그럼 이 사이트를 이용하여 앞서 설명한 해시함수의 특징을 간단한 테스트와 함께 다시 이해해보도록 하겠습니다.
- 어떤 입력 값에도 항상 고정된 길이의 해시값을 출력한다.
위의 특징은 다시 말해서 입력 값이 엄청 긴 그러니간 책을 한권 분량의 데이터를 넣어도 항상 고정된 값의 해시 값을 출력한다고 했습니다.
우선 작은 수의 글자를 입력하기 위해'어미새'를 먼저 입력하고 결과 값을 확인해 보겠습니다.
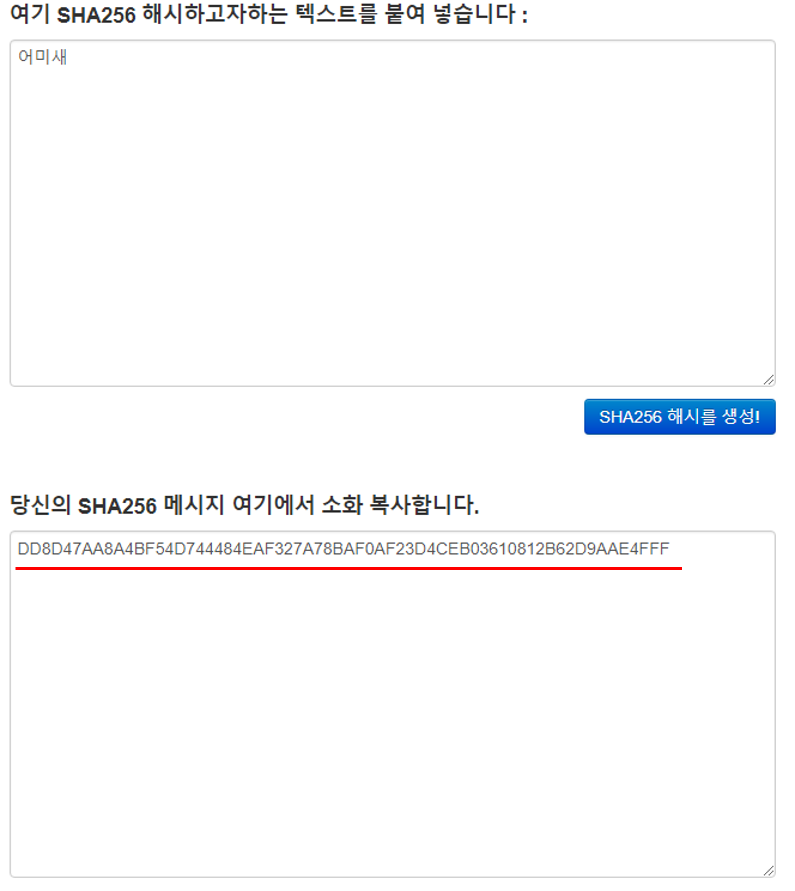
결과 값은 256비트(32바이트)데이터의 길이로 출력된 것을 확인할 수 있습니다.
이번에는 조금 긴 문자열을 넣어보도록 하겠습니다.
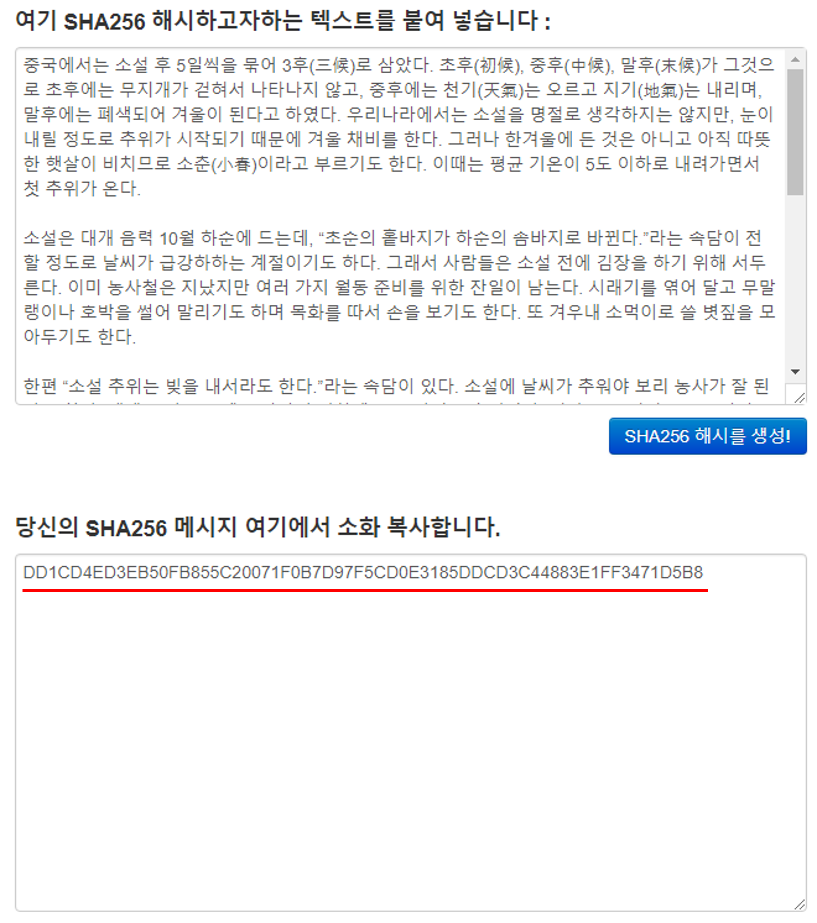
결과 값 처럼 입력 길이에 상관없이 항상 고정된 문자열의 길이를 반환하는 특징을 확인할 수 있습니다.
그렇다면 이러한 특징을 어떻게 활용할 수 있을까요?
이 내용을 설명하기 위해서 먼저 해시 함수의 2번째 특징인 눈사태 효과에 대한 설명이 먼저 필요합니다.
2.눈사태 효과 : 입력 값의 아주 일부만 변경되어도 전혀 다른 결과 값을 출력한다.
입력 값의 아주 일부만 변경되어도 전혀 다른 결과 값을 출력하는 특징입니다.
먼저 'Hello word'라는 단어를 입력하고 결과 값을 출력해보겠습니다.
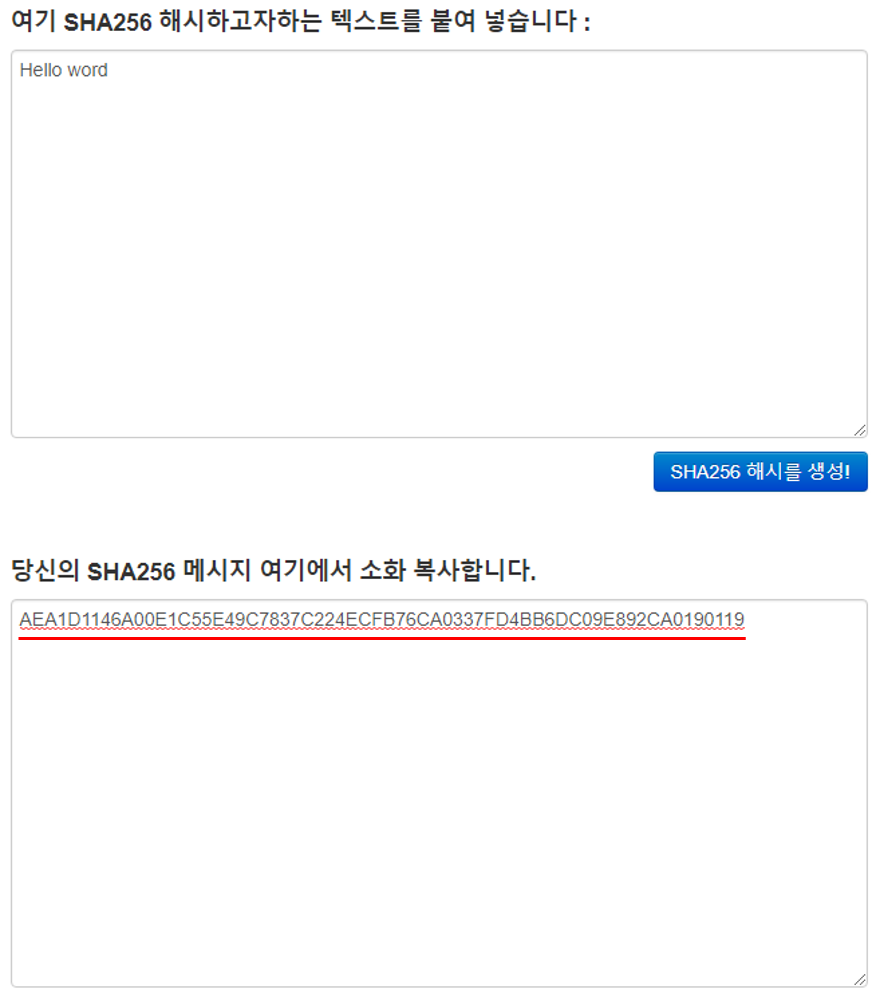
아래와 같은 결과 값이 출력되었습니다.
AEA1D1146A00E1C55E49C7837C224ECFB76CA0337FD4BB6DC09E892CA0190119
그렇다면 이번에는 마지막에 s를 붙여 'Hello words'를 입력하고 결과 값을 출력해보겠습니다.
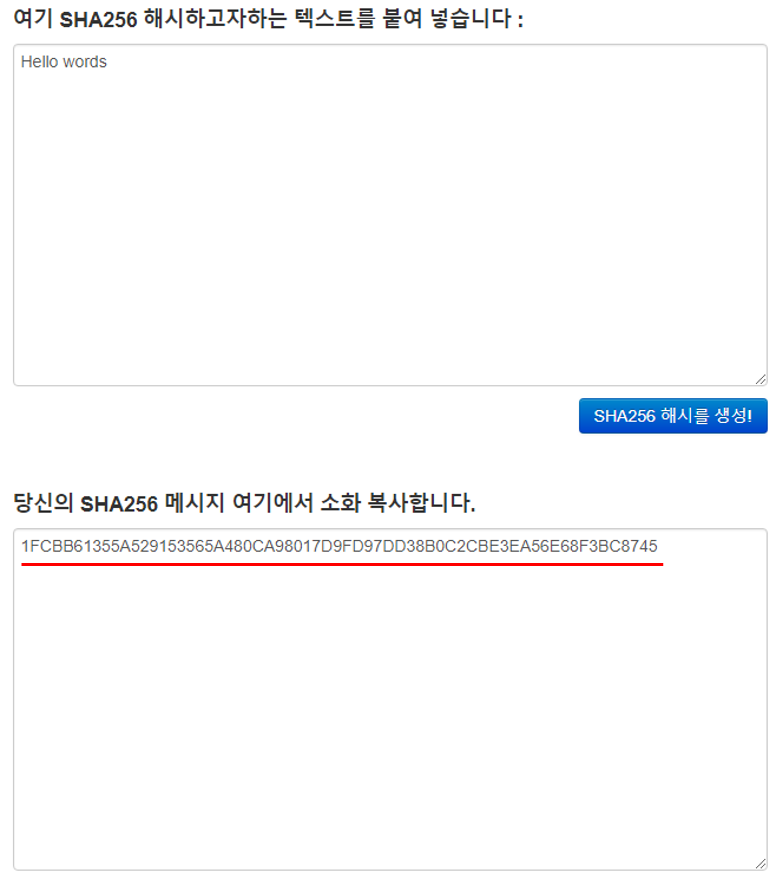
아래와 같은 결과 값이 출력되었습니다.
1FCBB61355A529153565A480CA98017D9FD97DD38B0C2CBE3EA56E68F3BC8745
입력 값은 아주 조금 변경되었지만 출력 값은 전혀 다른 결과가 나왔습니다.
즉 여기서 3번째 특징인 출력 값을 토대로 입력 값을 알 수 없다는 특징이 이해가 되실겁니다.
입력값의 일부만 변경되었을 뿐인데 이렇게 전혀 다른 값으로 출력된다면 출력된 결과 값을 토대로 입력값을 유추하는건 불가능할겁니다.
자 그럼 아주 방대한 데이터의 내용이 변경되었는지 확인하는 과정이 있다고 생각해봅시다.
그럼 데이터가 변경되었는지 한글자 한글자식 비교한다면 아주 오랜 시간이 소요될겁니다.
하지만 해시함수를 이용한다면 어떤 길이의 입력값이라도 256비트의 고정된 결과값을 출력할 것이고
입력값의 아주 일부만 변경되어도 전혀 다른 값이 출력되는 특징 때문에 데이터가 변경되었는지 쉽게 확인할 수 있습니다.
추가적으로 해시함수는 입력된 값이 같을 경우 항상 같은 결과 값을 출력해야합니다.
입력된 값은 같으나 다른 결과가 나온다면 데이터의 무결성을 검증할 수 없겠죠?
그리고 입력된 결과 값은 다르지만 같은 결과 값이 출력될 경우가 있습니다. (이련 경우는 아주~ 아주~~~ 희박하다고 합니다.) 입력 값이 다르지만 같은 결과 값이 출력되는 경우를 충돌이라고 표현하며, 충돌이 적은 해시함수가 좋은 해시함수가 되겠습니다.
다음 포스팅에서는 블록체인 기술에대한 간략한 개념정리와 블록의 구성요소에 대하여 포스팅 하도록 하겠습니다.
긴 글 읽어주셔서 감사합니다!
다음편 보기 / #3 - 블록체인 기술 및 블록에 관한 정의
(@yahweh87/3)
[참고 사이트]
https://blog.iwanhae.ga/introduction_of_bitcoin/