
Here I will show you how to use IBM Watson and Python to read text from images. Practicality? Yes, I'm glad you asked:
- license plate recognition (from real time video feed - cc cams, ip cams, etc.)
- recognizing and storing id information from photos (sites that use photo-id verification)
- converting photos of pages from books to documents, to pdf, etc.
- basically, any kind of text information gathering from images and video feeds.
You could create a script that would run over a video-feed (your ip cam) that looks over your parking spot and whenever it finds a car with a different plate number (that has illegally parked in your spot) than your car it takes a snapshot. You could further use the information at your disposal :)
Text Recognition with Watson and Python
We will use the IBM Watson Visual Recognition API and we'll call it from Python. I'm doing this under Windows 8 64-bit OS.
Watson is an IBM product. It's basically a complex computer algorithm that makes use of machine learning technology to reveal insights from unstructured data, usually very large amounts of data. To avoid repeating myself, please see the first tutorial I did for Watson and Python. It is a prerequisite if you want to follow along with this one.
Hence, I'm going to make a couple of assumptions:
- you have a Bluemix account (free)
- you have Python installed
- you have the watson_developer_cloud module in Python
- you have setup the Visual Recognition API in Bluemix
All these pre-requisites are explained in detail in part 1.
Now, here comes the easy part.
1. Open the Python command line and run the following
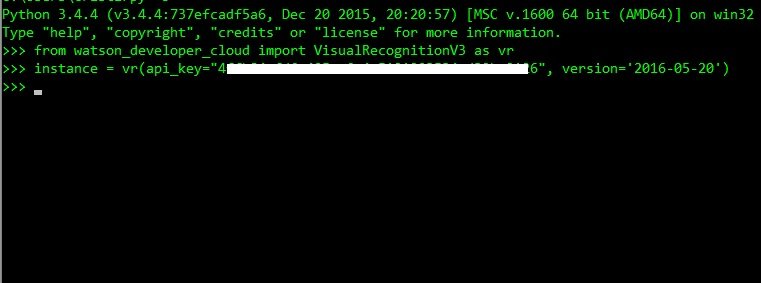
from watson_developer_cloud import VisualRecognitionV3 as vr
instance = vr(api_key='paste your api _key here', version='2016-05-20')
2. Select an image (local or url) and run the text recognition feature. For this tutorial I'm using this image:

And I run the following commands:
img = instance.recognize_text(images_url='url-path-to-img.jpg')
If I type in 'img' in the command-line I get the full result:
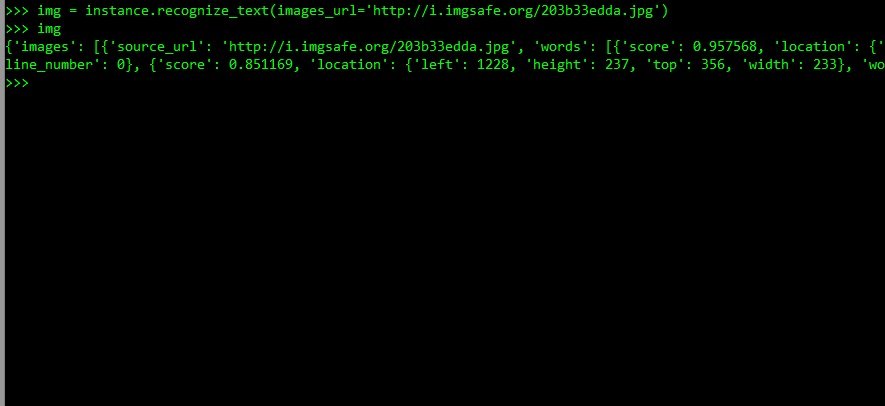
It gives us the location of the characters and other relevant information. But we only need the text. So, to get it, I run the following command:
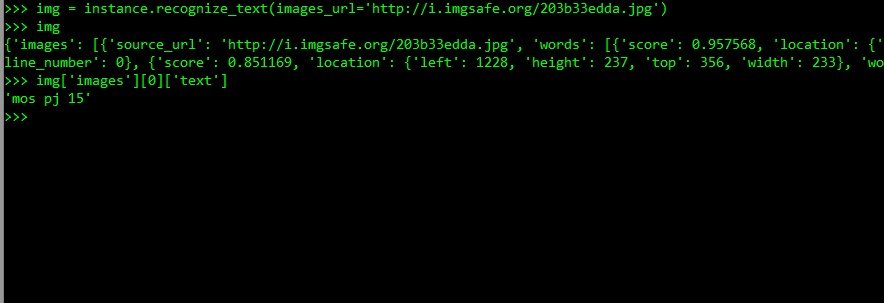
img['images'][0]['text']
Which returns the text from the image ('mos pj 15').
Additionally...
There are other features of the Visual Recognition API that you can use:
- 'instance.classify(...' to recognize objects and themes in the images (tutorial 1)
- 'instance.detect_faces('...'
- and others.
In your Python Command line, you can run:
help(instance)
And you'll get the full documentation, often with examples. Happy coding!
To stay in touch, follow @cristi
#programming #machinelearning #python
Cristi Vlad, Self-Experimenter and Author