在之前的一篇文章中,我曾经设想过读取某个时间段内的区块,尽管最后没能成功,但却提供了一个思路。

(图源 :pixabay)
20多天过去了,今天我决定抽出时间来实现一下当初的设想,首先我们简化一下问题,读取时间段内的区块,我们只需知道时间点1对应的区块编号以及时间点2对应的区块编号即可,那么这个这个文件可以简化为:如何获取指定时间点的区块编号?
原理
获取指定时间点的区块编号基于以下原理:
- 每个区块都有时间戳(timestamp)
- 两个相邻区块之间的时间间隔为3秒
那么我们拿任意块的时间戳与我们指定的时间点之间的差额,即可计算出中间间隔了多少块,进而计算出目标区块的编号。
换成简单代码逻辑就是:
db_base = Block(base_num).time()
seconds = dp - dp_base
blocks_diff = int(seconds / 3)
block_num = base_num + blocks_diff
问题
但是上述伪代码改成成实际代码并执行后,计算出来的区块编号(block_num)对应区块的时间和我们的目标时间点之间存在较大的差异,这是什么原因导致的呢?
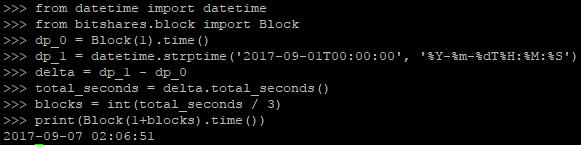
比如上图,我们实现了一个粗糙版本的代码用于测试,但是我们期望读到2017-09-01T00:00:00的数据块,但是读出来的区块对应的时间为2017-09-07 02:06:51
经过分析,我得出结论,实际区块产生的时间间隔不是精准的3秒,而是可能会略大于此数值,所以会导致我们的计算有所偏差。
解决
知道了原理,以及存在的问题,以及导致问题的原因,我们就可以做出更加完善的代码,来获取指定时间点的区块编号了。
我们采取的办法是逐渐逼近法,以上边代码为例,我们通过指定时间点以及基准块获取到一个区块的时间点,我们如果这个时间点与目标时间点差异较大,我们则用这个时间点对应的区块作为基准块,重新去获取目标区块。知道我们找到符合条件的区块。
代码
为了更好完成上述任务,我实现了一个粗糙的函数:
def find_block_by_time(data_point, base):
print("\tBase:", base)
dp = Block(base).time()
delta = data_point - dp
diff_seconds = delta.total_seconds()
if abs(diff_seconds) > 3:
diff_blocks = int(diff_seconds / 3)
base += diff_blocks
block_num = find_block_by_time(data_point, base)
return block_num
else:
return base
好吧,其实命名应该叫find_block_num_by_time,懒得改了,不然怎么对得起粗糙的称号呢?
测试
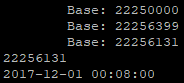
例子一:指定邻近区块为基准
dp = datetime.strptime('2017-12-01T00:08:00', '%Y-%m-%dT%H:%M:%S')
block_num = find_block_by_time(dp, base=22250000)
print(block_num)
print(Block(block_num).time())
例子二:指定创世块为基准
dp = datetime.strptime('2017-12-01T00:08:00', '%Y-%m-%dT%H:%M:%S')
block_num = find_block_by_time(dp, base=1)
print(block_num)
print(Block(block_num).time())
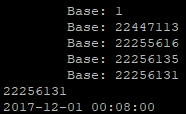
通过例子可见我们都完美地返回了正确的结果,但是例子一计算了2次,而例子二计算了四次,由此可见距离越近,计算得越快。
另外,我们程序只得到时间点临近的块,可能是正好的时间点,可能是之前或是之后,如果想得到不同的结果,需要将结果与时间点对比,判断出是之前还是之后,并根据需求+1或者-1即可。
用途

(图源 :pixabay)
至于有啥用途,你自己想去吧,我倒是觉得挺好玩的,哈哈。
文中代码仅为思路演示,不保证无误,仅供参考