在之前的文章中,我们学习过Python中使用Requests访问STEEM RPC。通过学习,我们了解到Requests是一个强大而易用的库,用来实现网络访问功能简直舒服的不得了,一库在手,天下我有。

(图源:bing.com)
然而,人生不就是折腾嘛,不折腾到淋漓尽致不痛快,所以我今天又去学了一下使用urllib如何访问STEEM RPC节点。
继续那我们之前的命令为例:
curl --data '{"jsonrpc": "2.0", "method": "call", "params": ["account_by_key_api", "get_key_references", [["STM6MGdForcZ8HskcguP84QSCb8udgz7W9yUPU5jtsAKQAxth3U16"]]], "id": 1}' https://api.steemit.com
urllib访问STEEM RPC节点
使用urllib将如何实现呢?
其实代码也很简单,示例如下:
import urllib.request
import json
rpc = "https://api.steemit.com"
payload = {"jsonrpc": "2.0", "method": "call", "params": ["account_by_key_api", "get_key_references", [["STM6MGdForcZ8HskcguP84QSCb8udgz7W9yUPU5jtsAKQAxth3U16"]]], "id": 1}
data = json.dumps(payload)
data = data.encode('utf-8')
with urllib.request.urlopen(rpc, data) as f:
print(f.read().decode('utf-8'))
运行上述代码段,输出如下:
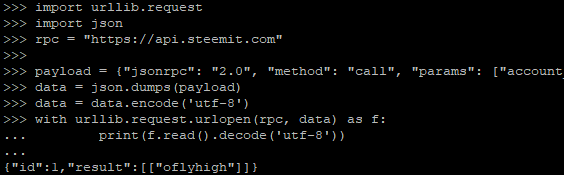
可见与Requests的输入没有什么大不同。
代码说明
如果我们对比一下 urllib与Requests访问STEEM RPC的代码,就不难发现,urllib代码中多了一句:data = data.encode('utf-8')
如果我们不加上这句,就会出现如下错误:
TypeError: POST data should be bytes, an iterable of bytes, or a file object. It cannot be of type str
另外,在官网的POST示例中,使用如下代码处理POST数据
import urllib.parse
data = urllib.parse.urlencode({'spam': 1, 'eggs': 2, 'bacon': 0})
data = data.encode('ascii')
因为我们只需POST JSON转储的字符串,所以无需也不能使用urlencode对数据进行编码
关于data.encode('utf-8')以及f.read().decode('utf-8')因为我们post和return的都是ASCII数据,而ASCII数据编码成UTF-8之后,没啥变化,反之亦然,所以此处用ascii和utf-8都可以。但是如果是处理其它网页,使用错误的编码就可能导致乱码等问题。
你可能会问,steem上的文章有中文文章,有汉字,那怎么还是ASCII编码呢?答案在于,返回的数据是使用json.dumps转储的,utf-8字符也被处理成ASCII啦。比如我的一篇文章标题,就是这个样子:
"title":"\\u56de\\u5fc6\\u5f55\\u4e4b\\uff1a\\u6587\\u6863\\u683c\\u5f0f\\u7684\\u65e7\\u4e8b"
实际上它应该是这样:回忆录之:文档格式的旧事
高级功能
之前介绍Requests时提到,什么Session啊,keep-alive啊都是直接支持的。在urllib中如何实现呢?
我大致了解了一下,urllib中没提到咋实现keep-alive,倒是在HTTP modules中的http.client可以支持keep-alive,但是这属于另外一个话题了,而且,在http.client的页面写着如下内容:
This module defines classes which implement the client side of the HTTP and HTTPS protocols. It is normally not used directly — the module urllib.request uses it to handle URLs that use HTTP and HTTPS.
我觉得我有点方,如此看来,还是Requests好呀。