在半个月以前,我介绍过一个强大并且易于使用的Python HTTP 库:Requests,并且在文章中提及了Requests的会话(Session)中可以自动实现持久链接(Keep-Alive)。
但是古人教导我们纸上得来终觉浅,绝知此事要躬行,不实际演练一下,我总觉得不放心,于是写个小程序测试一下。

思路
我们做一些小程序,遍历获得几个用户的用户ID以及用户名。通过对比程序执行时间,来看看Keep-Alive是否生效。
其实这个是可以通过一个API一下子返回的,那么就一次连接岂不是无法彰显Keep-Alive的作用了,所以就用笨方法喽。
代码
import requests
import json
import time
users = ['lemooljiang', 'ace108', 'oflyhigh', 'deanliu', 'rivalhw']
rpc = "https://api.steemit.com"
start = time.time()
for user in users:
payload = {"jsonrpc": "2.0", "method": "call", "params": ["database_api", "get_accounts", [[user]]], "id": 1}
r = requests.post(rpc, data=json.dumps(payload).encode('utf-8'))
json_r = json.loads(r.text)
print("id:", json_r['result'][0]['id'], "\tname:", json_r['result'][0]['name'])
end = time.time()
print("Execution Time: ", end - start)
session = requests.session()
start = time.time()
for user in users:
payload = {"jsonrpc": "2.0", "method": "call", "params": ["database_api", "get_accounts", [[user]]], "id": 1}
r = session.post(rpc, data=json.dumps(payload).encode('utf-8'))
json_r = json.loads(r.text)
print("id:", json_r['result'][0]['id'], "\tname:", json_r['result'][0]['name'])
end = time.time()
print("Execution Time: ", end - start)
执行结果
以下为上述程序执行结果:
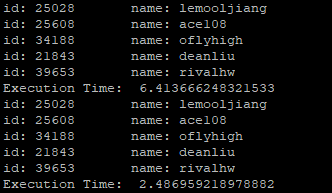
对比可知,使用Session程序效率大幅提高,这就是Keep-Alive的神奇之处哦。
尽管效率提升很明显,约2-3倍,但是没到很夸张的地步,比如10倍8倍,这是因为我们get_accounts取回的数据量很大,如果数据量很小,网络操作频繁的话,就会更加明显啦。
验证
你可能说,尽管效率提升了,但是一定是Keep-Alive的功劳吗?也许就是Session干了啥不为人知的提升效率的勾当呢?
我们在代码中加入如下语句来打印DEBUG信息
import logging
logging.basicConfig(level=logging.DEBUG)
我们把程序结果分成两部分截屏,便于比较
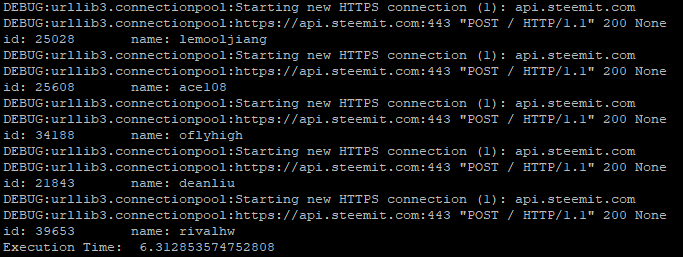
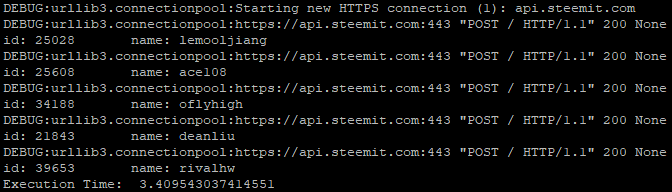
通过对比,我们很容易就发现如下规律:
- 第一段程序每次都创建连接,再请求数据
- 第二段程序仅创建一次连接,然后每次请求数据即可
并且我们捎带发现一个秘密,Requests用的urllib3哦。
结论
Requests的会话(Session)中可以自动实现持久链接(Keep-Alive),可以极大程度提升程序的效率,尤其是网络操作频繁的程序。