The CERN Large Hadron Collider, the LHC, is the largest particle physics accelerator complex ever built. Since a few years, several experiments are recording data, and my experimentalist colleagues are running analysis to explore deeper the world of the elementary particles.
All of this has been achieved with significant human and financial efforts, and I definitely believe that the society gets something out of it, as I have already discussed here. The point I want to discuss today lies towards data preservation and how could this data be used in the future, maybe in 25-50 years?
This is a question I started to investigate 7 years ago and I will share my thoughts and the actions I have undertaken since then. As this problem is a really important one for particle physics, I will take very seriously any comment! So do not hesitate!
I will also detail the current needs with respect to my vision of the problem and maybe how non-physicists could help. This could actually be a first particle physics project running on Steemit, depending on the interest of course.
 [image credits: CERN]
[image credits: CERN]
DATA PRESERVATION AND ACCESS - THE STATUS
Dedicated working groups have started to study how the large amount of LHC data could be preserved, made open access and reused.
To give an idea of why this is a non-trivial issue, the LHC produces about 25 GB of data per second. Only 1 MB of data per second is however stored thanks to powerful algorithms allowing us to sort non-interesting from interesting data. Not all non-interesting data is however thrown away as it is important to also verify that the behavior in there is the one expected. At the end of the day, this consists of a huge amount of data to be preserved and possibly released.
The CMS collaboration has recently released (last April) half of the data collected by the collaboration in 2011, which consists of 300 TB of high-quality data. The ALICE collaboration has planned to release a first bunch of data in 2018, and nothing is known so far for ATLAS and LHCb.
IS IT ONLY WHAT WE NEED?
Am I happy with data being released? Of course I am, but this is not very helpful for most of the high-energy physics community.
Let us assume (or dream, please choose) that within a few years, a specific physics model starts to emerge as a big picture from data. It is important to test it, in particular with respect to all previous LHC results. This means that a lot of work has to be carried:
- implementing the model in the LHC simulation tools and validating this implementation;
- simulating LHC collisions when the new model is accounted for;
- confront the model to data.
And now let us multiply these tasks by the number of model candidates that could equally explain all results...
STEP1 - PROBLEM SOLVED
 [image credits: pixabay ]
[image credits: pixabay ]
The first step was very complicated more than 10 years ago. Then comes automation. It is now sufficient to feed a computer with a Lagrangian (the equation containing all the physics) to recover, as an output, a python version of the model that can be imported into the tools.
This pythonic way of handling physics models is now a standard in the particle physics community (and is called the UFO). For those who likes stories, this (including the choice of the UFO name) has been developed in March 2010 by a bunch of physicists isolated in a monastery in the Vosgian mountains (but with beers and wifi available).
STEPS 2 AND 3 - THE REAL ISSUES
The second step (simulating LHC collisions) is more problematic. The problem is of course not to simulate the collisions themselves, as many tools are publicly available, open source and open access, but instead to mimic the detector response of the LHC detectors.
The official software packages used by ATLAS, CMS or other experiments have been developed by the experiments themselves and are non public. Even if they would become public, simulating one collision takes of the order of one or two minutes. To test a model, we need to try several (sometimes dozens of) combinations of the model parameters, and for each combination, we need to simulate hundred thousands collisions. Mission impossible.
And the story does not end here. The third step is also a problem. To confront the model predictions to real life, it is needed to analyze the model predictions in a similar way as was done by the experimental collaborations, i.e. to confront the model to the results of a given analysis. And this analysis must therefore exactly be reproduced. And hundreds of analyses have been performed by the LHC collaborations.
As the original analysis codes are private and properties of the collaborations, we need to develop computer codes that will perform the experimental analyses under consideration, and to validate these codes.
FORMULATING THE REAL PROBLEM: PRESERVING ALL EXISTING ANALYSES
Another group of physicists, still with beers, still in the mountains (but in a physics center in the Alps this time) have brought a tentative solution to the problems connected to the steps 2 and 3 above-mentioned.
They have proposed a new framework allowing to test models against data in an easy way. Their approach is based on:
- relying on a public detector simulator that one can tune easily, mimicking closely the real LHC detectors;
- relying on an easy-to-use C++ program that contains lots of useful methods for reimplementing the LHC analyses.
The results will be approximate, but good enough for rapidly testing model configurations and pin down those that survive all constraints.
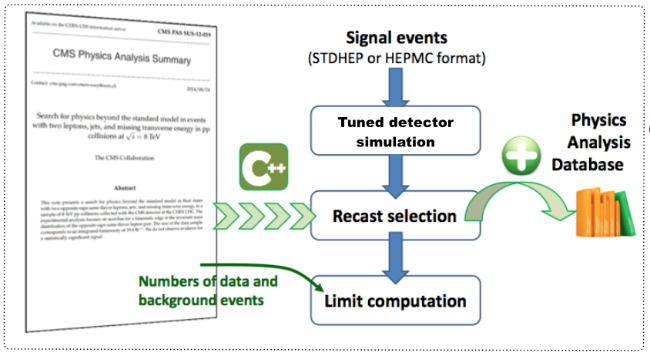
What to do to implement a new analysis so that the latter could be used to test physics models?
- First, one needs to read an experimental publication and hope it is correct and complete.
- Second, one must tune the detector simulator and implement the analysis in c++.
- Third, one needs to validate everything, or consider a given physics signal and compare official numbers with reimplemented results.
This last step is crucial for the analysis to be shared with the community and easily takes months. Getting the validation material takes ages, sometimes is a dead-end (sorry the student has quit physics), and we must understand whether any difference would point towards a bug or are a genuine feature of the approach.
CURRENT STATUS
This approach works pretty well, we have now about 20 analyses fully validated, publicly available and used by other scientists for their studies. We have also developed other features in the meantime that I believe are good for the community.
- All reimplemented codes are stored on Inspire, from where they are also versioned and freely available.
- They are attributed a Digital Object Identifier so that they can be cited by scientific articles.
- Code authors can collect citations for their reimplementation codes.
- The validation material is shared so that anyone can double-check what has been done for the validation and trust the reimplementations.
- We have developed a python program that allows one for automatically testing any physics model against data using all available reimplemented codes.
TOWARDS A FIRST PARTICLE PHYSICS CHALLENGE ON STEEMIT
The most urgent issue is to increase the size of the library containing our reimplemented codes.
Regarding the size of the team involved in the project (and the title of the post), we do not need a blockchain to be able to track down everything that was going on. And this is the key of the problem: we do not have enough manpower to be able to reimplement a reasonable number of analyses. Which may sound surprizing as many people are actually using the program (cf. citations). But that's life.
This project may however be spread beyond particle physics. Anyone who can code in c++ could actually participate. Therefore, why not on Steemit? I am here to help for the physics part, and the #steemSTEM is the perfect place for discussions :)
Would anyone like to invest some of his spare time working for the particle physics community? To be part of something great?
Before signing up, implementing a new analysis takes time. A lot of time. Easily a couple of weeks, sometimes a couple of months. So be ready for that. Then, concerning rewards, I can see plenty of them (and they are not exclusive):
- SBD and STEEM to share (status reports could also be written so that more will become available for sharing);
- Each participant will be the author of a computer code that can be used by the particle physics community and cited in scientific publications;
- We can imagine writing a scientific article if enough analyses are made public (to be published in an open access journal);
- I can grant a participation to all involved people to a workshop that I am organizing in Korea next summer on this LHC legacy topic (I cannot however cover the flights at the time we speak);
- Please name it, I will see what I can do (if possible).
TAKE HOME MESSAGE
In this post, I summarized my personal efforts for the legacy of the LHC and show what are the current problems. This changes from my usual posts on particle physics or cosmology, but it is also interesting to discuss real problems that our field is currently facing. I hope you enjoyed the reading and that at least some of you will accept the challenge!