I've finally setup my own full-RPC steemd node on a 6 core Xeon server with 256GB of ECC DDR4 RAM, in a datacenter nearby SteemData (over private, 1gbit network with sub 1ms network latency).
Running a full node is an additional maintenance workload, but it seems to be no longer avoidable. I hope that this new deployment, in combination with @gtg's node as a backup, will improve speed and reliability of SteemData services.
Public Steemd Nodes
Steemit's official nodes have been rock solid in the past month, and served well as a backbone for many of my services. I have also used @gtg's nodes extensively, since they are hosted in EU.
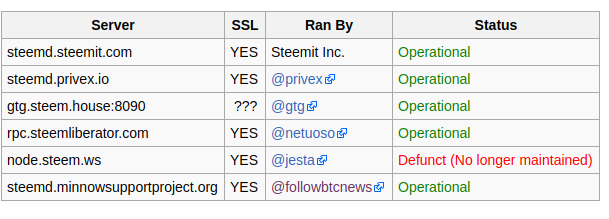
I am really happy about the proliferation of full steemd RPC nodes by the community, however I haven't had a chance to extensively test them yet.
Why Private node?
I currently run 3 databases as a service, and attempt to maintain steemd internal state synced up to the main SteemData database. I'm also syncing up the new databases from scratch (hive, sbds). All in all I'm currently performing millions of requests daily to steemd instances.
Unfortunately, SteemData servers are located in Germany, which adds a fair amount of network latency to most of the public nodes I tested. The per-request network latency, as well as limitations on available throughput were causing some issues, as the database indexers could not catch up with the blockchain head.
Why 256GB of RAM?
It is possible to run RPC nodes on hardware with lower specs, but unfortunately my needs require the fully specced out setup.
Reducing memory usage by selectively enabling features
It is possible to run RPC nodes with lower requirements. For one, not every app needs all the plugins. An app like Busy or Dtube doesn't need the markets plugin for example.
Secondly, its possible to blacklist certain operations from being indexed in account history plugin, which can also drastically reduce memory usage.
The point of SteemData is to process and store all the available information, so these optimizations do not apply.
Using SSD instead
Without high throughput and low latency requirements, its possible to run the shared memory file on a SSD. By doing so, a full RPC node could be hosted on a server with as little as 16GB of ram.
SteemData is making a lot of arbitrary requests, and to stay near-real time in state synchronization, the throughput and latency are crucial. Which is why I need all of the state to be mapped out in RAM, and the node be hosted in the same datacenter as the rest of SteemData servers. This setup is an over-kill during normal operations, but very much needed when syncing up from scratch.
Setup
I've made a custom docker image, based on Steemit's. (Dockerfile, run-steemd.sh)
I've assigned 200GB of 'ramdisk' for shared memory file, using ramfs,
with the following fstab entry:
ramfs /dev/shm ramfs defaults,noexec,nosuid,size=210GB 0 0
.
I've adopted @gtg's awesome full node config as a base, and tweaked it a bit.
rpc-endpoint = 0.0.0.0:8090
p2p-max-connections = 200
public-api = database_api login_api account_by_key_api network_broadcast_api tag_api follow_api market_history_api raw_block_api
enable-plugin = witness account_history account_by_key tags follow market_history raw_block
enable-stale-production = false
required-participation = false
shared-file-size = 200G
shared-file-dir = /shm/steem
seed-node = 149.56.108.203:2001 # @krnel (CA)
seed-node = anyx.co:2001 # @anyx (CA)
seed-node = gtg.steem.house:2001 # @gtg (PL)
seed-node = seed.jesta.us:2001 # @jesta (US)
seed-node = 212.117.213.186:2016 # @liondani (SWISS)
seed-node = seed.riversteem.com:2001 # @riverhead (NL)
seed-node = seed.steemd.com:34191 # @roadscape (US)
seed-node = seed.steemnodes.com:2001 # @wackou (NL)
.
Lastly, I run everything in Docker.
docker run -v /home/steem_rpc_data:/witness_node_data_dir \
-v /root/fullnode.config.ini:/witness_node_data_dir/config.ini \
-v /dev/shm:/shm \
-p 8090:8090 -d \
furion/steemr
Conclusion
This setup is fairly new (in production for less than 1 day), but the results are already promising. The syncing speed is more than 100x faster vs using remote nodes, and I haven't ran into any throughput limitations yet. As long as the node doesn't crash, things should be golden.