今天想用程序看一下自己的过往文章,用到的API是get_blog,原本想着是手到擒来的问题,没想到竟然遇到了问题。

(图源 :pixabay)
get_blog API
get_blog 用起来是很简单的,它有三个参数
account: 带获取的用户名start_entry_id: 开始blog编号limit:获取条目限制
其中start_entry_id即为开始从此entry_id向前查找。
entry_id我们可以理解成我们blog中文章(以及转发)的编号,最早的文章编号为0。但是API不支持获取直接读取entry_id为0的文章,因为start_entry_id为零代表最大的文章编号,也就是最新一篇文章。
如果想获取第0篇文章,我们可以将start_entry_id设置为1,然后limit设置成2,就会读回编号为1和0的文章。
以 @ned 为例
获取他的最早5篇文章,指令如下:
curl --data '{"jsonrpc": "2.0", "method": "call", "params": ["get_blog", "get_blog", ["ned", 4, 5]], "id": 1}' https://api.steemit.com
获取他的最新5篇文章,指令如下:
curl --data '{"jsonrpc": "2.0", "method": "call", "params": ["get_blog", "get_blog", ["ned", 0, 5]], "id": 1}' https://api.steemit.com
无法读取到500篇以上内容
一切看起来没有什么问题,但是当我尝试获取我的最早期文章时,返回为空!
curl --data '{"jsonrpc": "2.0", "method": "call", "params": ["get_blog", "get_blog", ["oflyhigh", 4, 5]], "id": 1}' https://api.steemit.com
返回如下:
{'id': 1, 'jsonrpc': '2.0', 'result': []}
这是什么鬼?我首先想到难道就因为我不是创始人之一,就搞歧视吗?后来想想开源代码不会有这么变态的判断吧,一定是哪里搞错了。
于是我不断尝试,最终发现我可以获取我最近500篇文章(包含转发)。
问题所在
看了一下代码,但是限制了limit大小为500,但是这个限制的是单次读取的数目啊,我应该可以通过指定start_entry_id和limit获取任意条目才对。
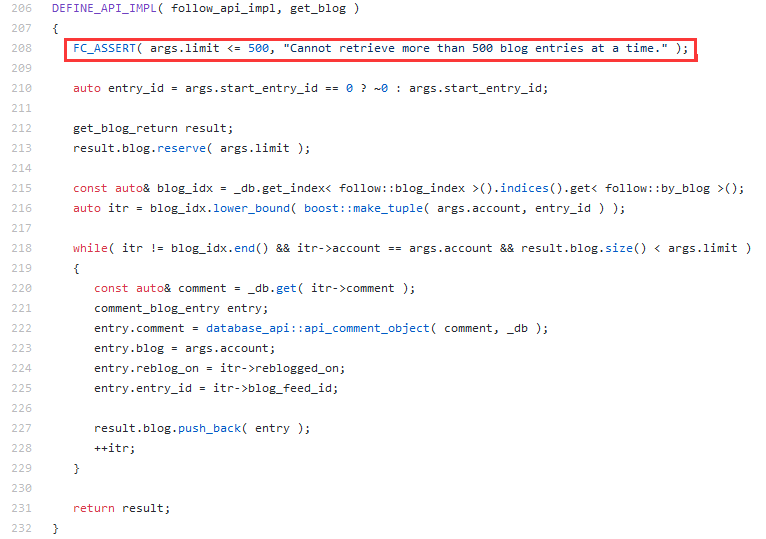
上述代码中没能看出什么其它限制相关的。
于是我在想,是不是最多就只能读出500条呢?最终我找到如下代码:
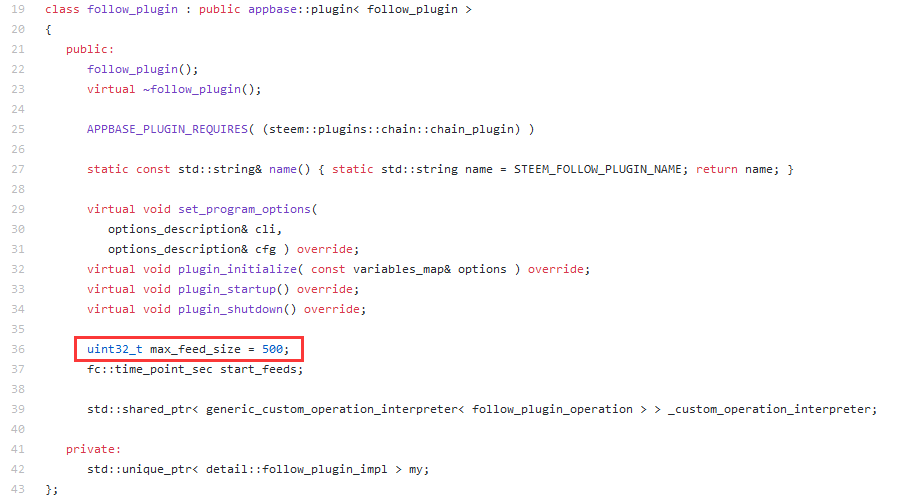
uint32_t max_feed_size = 500;
以及位于follow_plugin::plugin_initialize中的这段代码

如此我们得出结论,能读出多少条目,取决于节点的max_feed_size的设置,默认情况是500条。再深奥的,比如max_feed_size 如何在 comment_operation 以及reblog_operation发生时影响对相关索引做的修改,以及最终如何影响get_blog获取的条目数,我就读不懂啦。
STEEMIT如何处理这个问题
既然我们得出结论,由于节点max_feed_size的设置,我们无法读取某个用户500篇以前的文章,那么岂不是意味着如果某个用户的文章(加转发)数目大于500,我们将无法在STEEMIT从个人博客(blog)中读到这些用户的早期文章?
拿自己的账户试了一下,果然是这样!
翻我的主页,翻到这就再也翻不动了,在这之前,我可是还有近200篇文章呢😭 所以,STEEMIT如何处理这个问题?答案是STEEMIT根本没管这个问题!
如何翻阅早期文章?
尽管通过简单的阅读代码,我们知道了这个是系统就这么设置的,算不得BUG,但是不能阅读用户早期文章终归不爽啊。
那么如何翻阅用户早期文章呢?对于总计文章+转发低于500的用户,那么直接翻就可以了。
如果用户文章大于500,就需要一些其它手段喽,比如使用STEEMSQL或者STEEMDATA数据库等,这里就不再赘述了。大鹏 @dapeng 有个 steemr工具也不错,不过据说他要养活不起了😭