我们都知道STEEM每出21个块,重新选择一组(21个见证人),那么这组见证人是如何产生的呢?今天我们就来粗略地探究一下。

(图源 :pixabay)
每当出完一个块时,见证人选择函数都被调用update_witness_schedule,然后程序中判断是否是21的整数倍if( (db.head_block_num() % STEEM_MAX_WITNESSES) == 0 ),如果是则更新见证人列表 update_witness_schedule4,所以我们来看看这个函数内都做了什么就可以了。
这个函数结构很清晰,第一步就是选择见证人,代码上看这步可以分为三个部分
选择TOP 20见证人
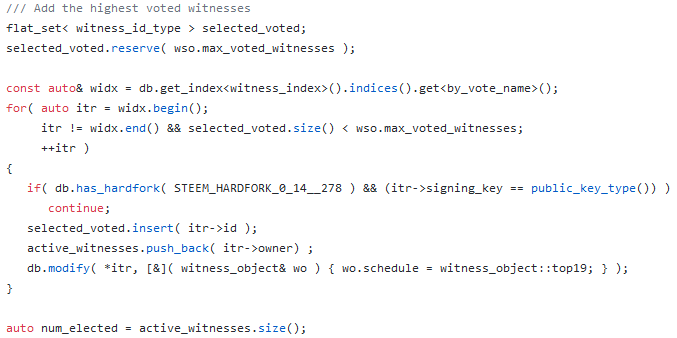
亦即按得票数多少,选择20名见证人。
有人可能会问,如果前二十名见证人有人占着位子,但是见证人离线(OFF LINE)了,被选上岂不是耽误事啦?别怕,以下代码表示如果有见证人离线,那么会略过,直到选够为止:

其中这句:
db.modify( *itr, [&]( witness_object& wo ) { wo.schedule = witness_object::top19; } );
其实应该是wo.type = XXXX,代表见证人类型,定义如下:
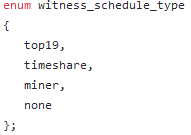
但是需要说明的是HF17之后,已经没有挖矿一说了,另外TOP19变成了TOP20,别被名字误导了。
选择矿工见证人
说到矿工见证人,之前我们说过HF17之后,没有挖矿一说,这个是如何体现的呢?
其实就是在HF17的代码 case STEEM_HARDFORK_0_17 分支下设置了如下数据:

上边三个常量分别对应20、0、1
我们可以获取witness_schedule_object来验证一下此事
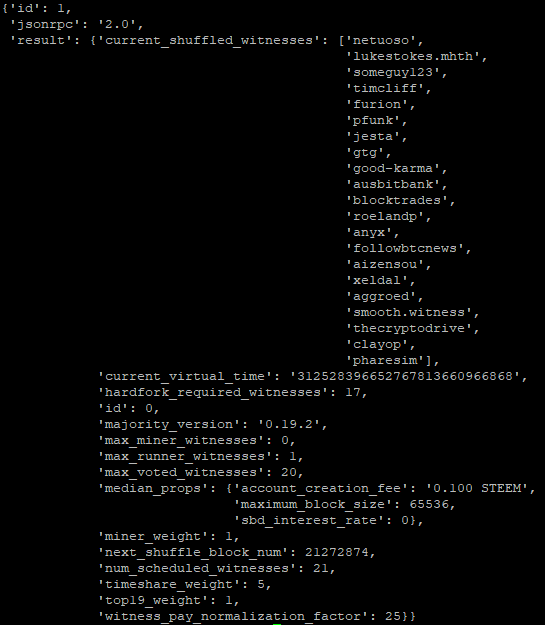
所以尽管选择见证人时,选择矿工的代码还在,实际上是啥也不做的。
选择轮值见证人
这个玩意该翻译成啥,我有点纠结,叫随机不合适,叫备选也不合适,代码中有的地方叫running,有的地方叫timeshare,我先翻译成轮值吧,这块是挺有意思的,也是我最关心的地方。

以上代码挺好理解,就是按拍好的顺序(by_schedule_time),选择一个见证人出来。当然必要的检查还得做做,比如看看是不是和TOP20或者矿工重复了、看看是不是离线,选出来还要设置一下类型等等。
但是,最最关键的问题是,这个schedule_time是咋排出来的? 接下来的代码就来解答疑问了:
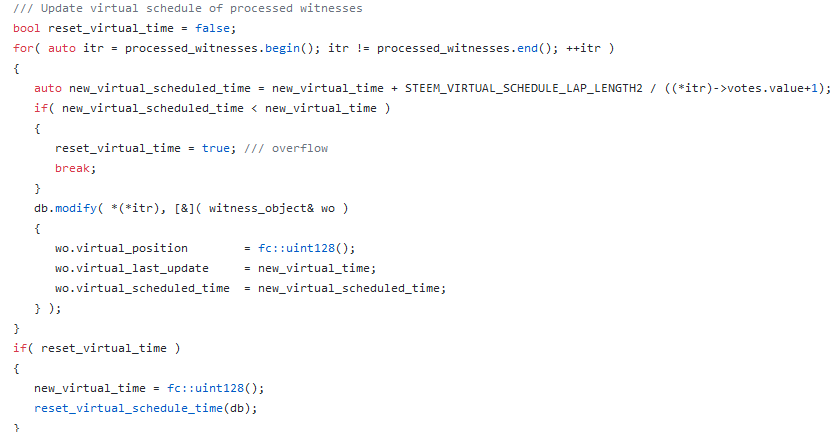
也就是说备选见证人有个排序的时间表,当然了,这里时间不是真正的时间,而是数轴上的一个点。用一个大数除以见证人的得票数,得到一个数,就是这个见证人下次轮值的时间。然后每次取这个数轴上的第一个点,也就是排在最前边的见证人了。
再回头看前边的代码:

每个被处理过的见证人,都会被重新排序,相当于你轮值过了再给你排下一班。
从以上代码不难看出,得票数越多,每次排序的点间距越小,那么被轮到的概率越高,所以我们之前说过的轮值见证人收益和得票数成比例,从代码上看是成立的。
总结
- 每21个块重新选一组见证人
- 见证人由TOP20 (20) + 轮值 (1) 组成
- 轮值见证人排到的概率和得票数成比例
在这之后的把选的这组见证人(21个)随机打乱的算法我实在是看不懂,不过我只需知道他打乱了一下就可以了,其它的我就不关心啦。好了,就写这么多啦!