Hi, Steemers!
In my previous posts (1 and 2) you could notice that I'm fond different mathematical concepts (e.g. machine learning and neural networks).
Here I would like to share and discuss with you basic problems of computer vision, such as object recognition and image classification. I explain basic principles of CV in plain language and hope you'll love this post.

Operating Principles of Simple and Complex Human Neurons
If typical neurons can define presence or lack of input signal, the neurons responsible for vision work as pattern detectors.
They answer a question: "Is there any specific pattern in the field of vision?". These neurons are called Complex Cells and located in the cerebral cortex. However Complex Cells consist of many Simple Cells, which can measure a matching of input image with pattern. In contrast to the Complex Cells, Simple Cells answer the question: "Does this image match the pattern?".
You can see difference between this two kinds of cells on the following pictures.
Simple Cells:
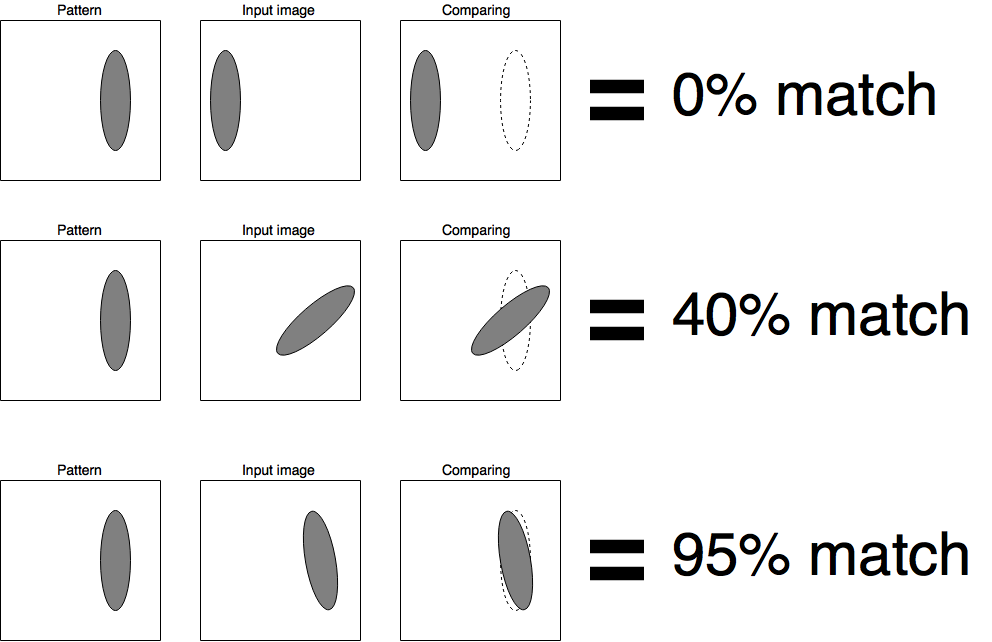
As you can notice simple cells can just overlay two images one of which is pattern. Each simple visual cell is in charge of recognition of simple pattern (e.g. vertical/horizontal/tilted line, arcs, circles).
Complex Cells:
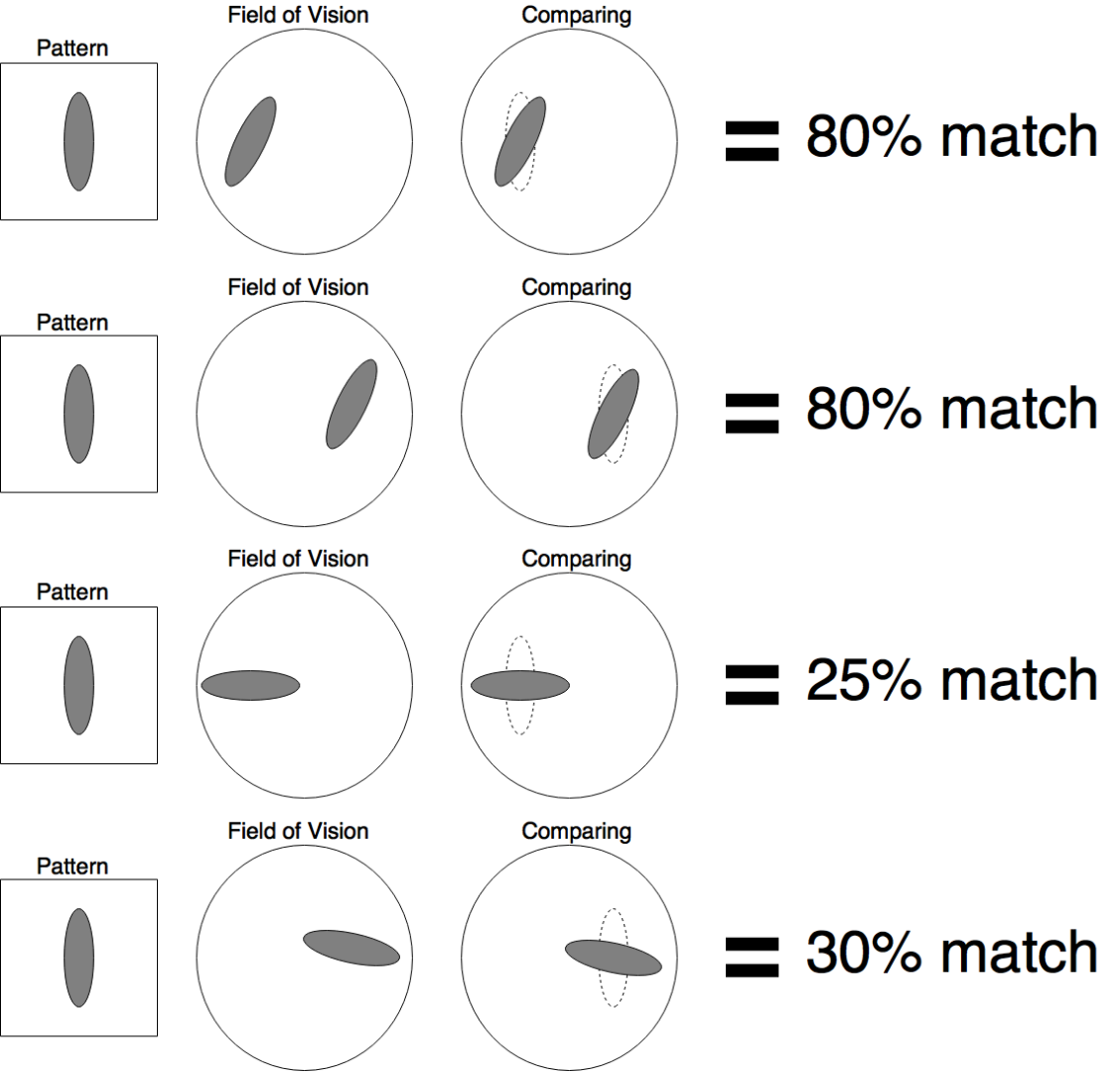
Complex cells can find object in any area of vision, even if it was moved to different place but they can't detect the pattern if it was rotated. The more match to pattern, the stronger output signal of the complex neuron.
Convolution as a way to reproduce the operating principles of humans vision
So now, after we understand the basic principles of humans vision we can construct its digital analogue, thus It's necessary to realize Complex Cells in math terms. Let's remember that in computers images are represented in a digital form. It means that we are dealing with matrices.
Firstly, let's reconstruct principles of Simple Cells in term of matrices. In other words let's define some operation with pattern matrix and input image matrix which allows us to measure similarity of objects. This operation is called Convolution. How does it work?
Let's see:
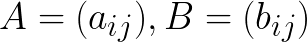 -
-
two matrices of dimension n x n that denotes pattern and input image respectively. Then convolution is calculated as follows:
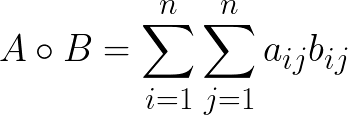
You can see that it's a simple dot product of vectors (if we consider the matrix as vector). And let's check how it works on simple examples. For simple neurons:
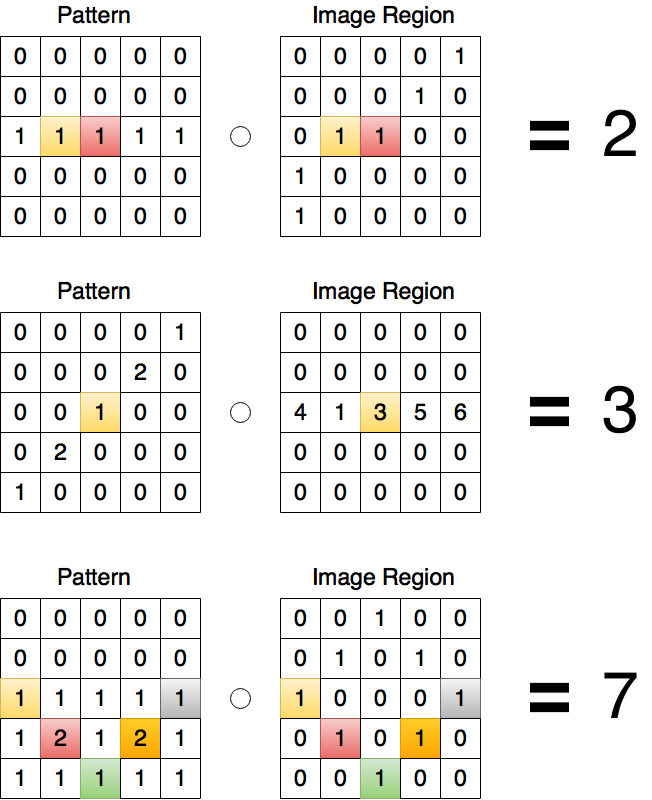
Colored cells denote multiplications that are not equal to zero. Sum of all the multiplications is convolution itself. Thus the more resulting convolution the more similarity between pattern and certain image region. This feature gives you the opportunity to find some pattern in a fixed image region (Simple Cell). But we want to detect existence of specific pattern in the entire image. For this we have to calculate all possible convolutions like this:
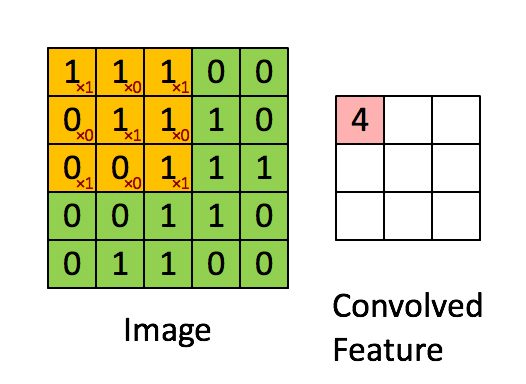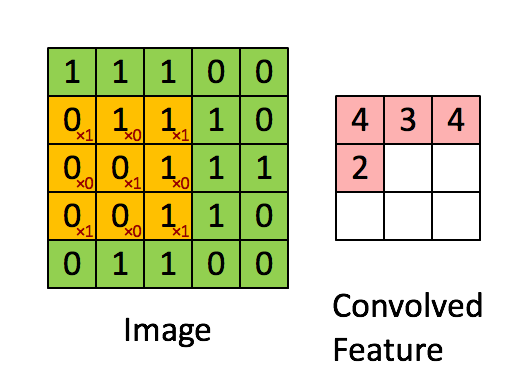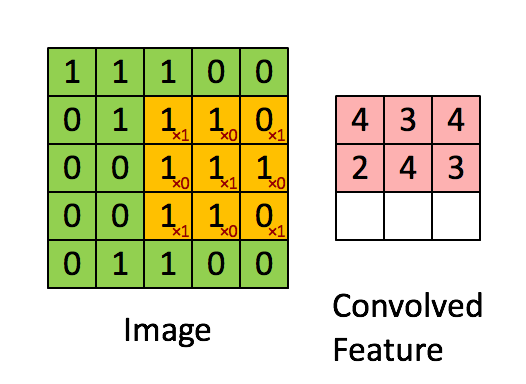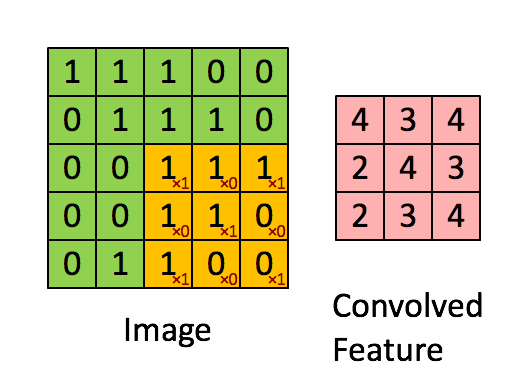
Matrix that we have as a result of this manipulation is called Feature Map (this term was mentioned by me in previous post about PRISMA app).
In order to get equivalent of the complex visual cell the one can pick maximal element of the Feature Map and the more the element the more probability of pattern presence. In that way we got mathematical model of humans complex neuron.
Image classification problem
The main and most popular task in the computer vision these days is to determine images content. This kind of technology is used by Internet companies to block adult content, by militaries to determine the number and equipment of enemy troops (e.g. by images from space), by google maps in their street view services to determine addresses.
Using the above models (we described only the basic principles but in fact various modifications are used), the solution of such problems becomes possible. Used in practice Convolution Neural Networks (CNN) consist of a certain number of consecutive convolutions with numerous filters. The most famous example of such a neural network is LeNet (LeCun Yan), that was the first ever CNN to detect handwritten numbers.
Problem of object detection
Usually images contain multiple objects and there is a problem of allocating subimages that contain separate objects for better classification. Different algorithms (based on edge-weighted graphs) are used for these purposes that are not connected with machine learning. In my previous posts I've also mentioned Computer Vision Lab Company. One of that guys has developed unique algorithm that can even compose sentences with image content description. I always admire on how this technology is useful for visually impared people.
As we can see the basic concept is pretty straightforward but there are plenty of obstacles that we have yet to overcome.
Every day these algorithms are improved and who knows, maybe someday the digital eye implants will become possible :)
Follow Me to learn more on Popular Science.
With Love,
Kate