
Introduction
This informative series of posts will explore modern biology; the fundamental principles of how living systems work. This material will always be presented at the level of a first-year college biology course, without assuming any prior background in biology or science. It also presents material in a conceptual format. Emphasizing the importance of broad, unifying principles, facts and details in the context of developing an overarching framework. Finally, the series takes a historical approach wherever possible. Explaining how key experiments and observations led to our current state of knowledge and introducing many of the people responsible for creating the modern science of biology.
This post will introduce the Central Dogma of molecular biology, which dictates that genetic information flows only in one direction, from DNA to RNA to proteins and not in reverse.
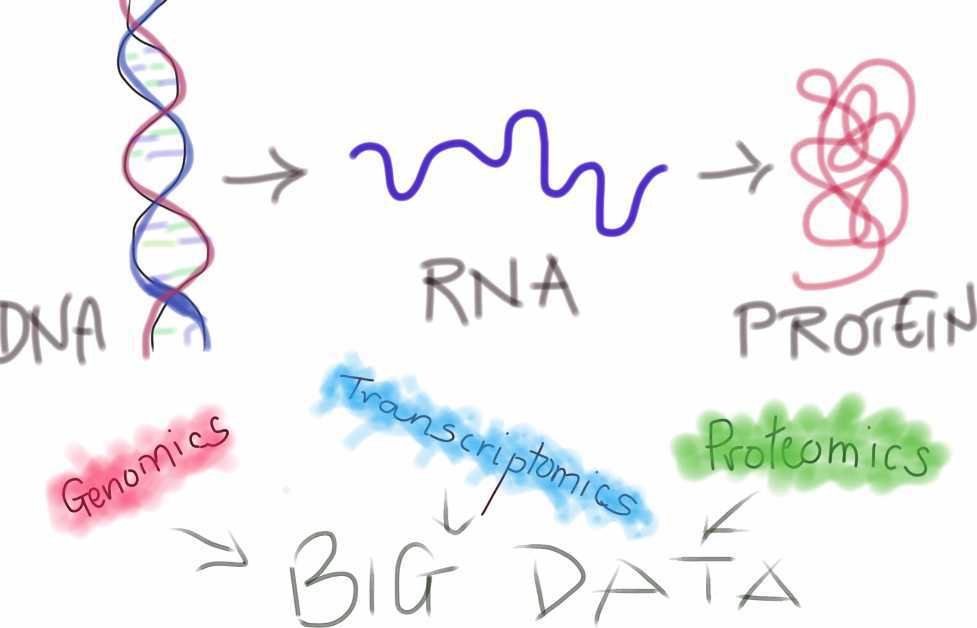
The Central Dogma serves as a broad conceptual framework for understanding how information stored in DNA is transformed into protein structure. We conclude this post with a discussion of RNA viruses and retroviruses, biological entities that serve as illustrative exceptions to the Central Dogma because they violate the typical path for the flow of genetic information. Retroviruses are particularly important in this regard because of their ability to reverse the normal direction of genetic information flow.
An information-bearing molecule in living systems must satisfy two requirements: It must provide a code to specify the structure of proteins, and it must be able to be replicated.
DNA satisfies the replication requirement, but we have not examined how it stores information. We do know, however, that a code needs to specify only the sequence of amino acids in a protein, which ultimately determines protein shape and function. Before we look at how this code might work, we need to take a broader look at how genetic information flows in living systems.
Francis Crick proposed what he called the Central Dogma of molecular biology, which is a conceptual model of genetic information flow comprised of two main points.
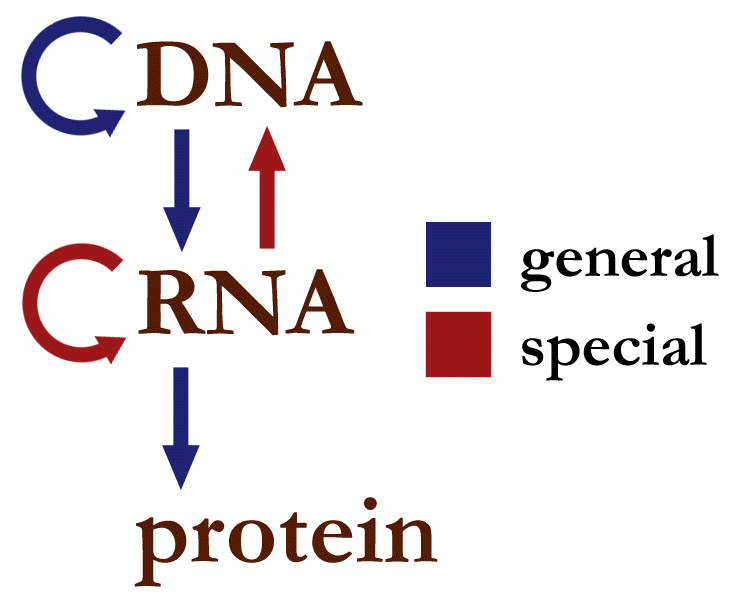
The first point is the suggestion that genetic information does not pass directly from DNA to proteins but passes through an intermediate molecule: ribonucleic acid, or RNA.
The second point is that information passes in only one direction, from DNA to RNA to proteins. Crick said, “Once information has passed into proteins, it cannot get out again.”
The nature of DNA gives rise to the one-way flow of genetic information described by the Central Dogma.

The information in DNA is stored as a sequential pattern of nucleotide bases. The process of replication transmits this information to newly synthesized DNA, preserving the sequential pattern. The information in DNA can be transmitted to a molecule of RNA through a process called transcription. The biochemical language of RNA is essentially the same as that of DNA, and RNA synthesis is similar in many respects to synthesis of new DNA. Information is not very useful in RNA. RNA’s main purpose is to pass genetic information to the process that builds proteins.
RNA structure is similar to DNA structure, with three important differences.

- The pentose sugar in RNA is called ribose and has a hydroxyl group in the second carbon position. The pentose in DNA lacks this hydroxyl group and is therefore deoxyribonucleic acid.
- In RNA, the base uracil (U) replaces the thymine (T) base found in DNA. Uracil forms a complementary base pair with adenine (A) in RNA.
- RNA usually occurs only in single-strand polymers, instead of DNA’s double helix.
There are several different types of RNA.
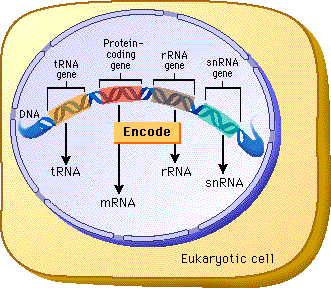
RNA that acts as an intermediate, or messenger, for information is called messenger RNA (mRNA). The information in mRNA is used to specify the structure of proteins through a process called translation. This term describes the process through which information is changed from its functionally useless form in DNA and RNA into the functionally useful form of proteins.
The Central Dogma provides a convenient framework for organizing our thinking about the molecular basis of genetic information.
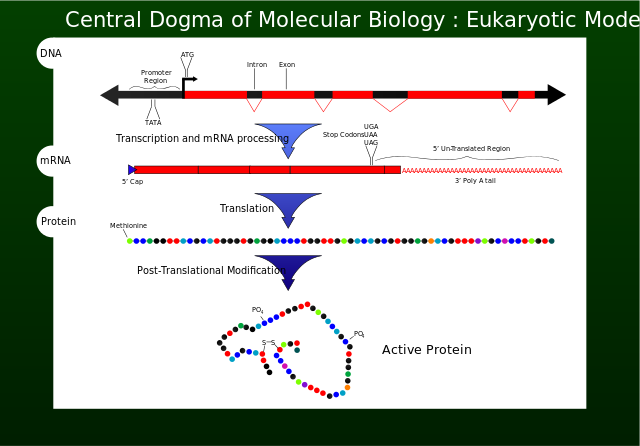
We have used the term gene loosely, but the Central Dogma makes clear that a gene must be, to a first approximation, a segment of DNA that carries the code for making a particular protein. Protein synthesis has many potential control points, which generally occur where information passes from one molecular form to another. Most important, the fact that genetic information can pass only from DNA to protein and not in reverse means that changes induced in proteins cannot feed back to the DNA coding for those proteins; DNA can be changed only if the DNA itself is modified directly. Because evolution is a change in the average characteristics of individuals in a population over time, evolutionary changes can be brought about only by changes to DNA itself. Changes to DNA can include copying errors or direct damage, but they are random and not influenced by the environment. Any change to DNA is called a mutation.
Notwithstanding its name, there are notable exceptions to the Central Dogma, representing cases in which the flow of genetic information does not follow the path from DNA to RNA to protein.
Many viruses, including for example the tobacco mosaic virus, use RNA as their primary genetic material. These viruses transcribe new RNA directly from other RNA strands, instead of from DNA, and generate proteins directly from RNA. Because the direction of information flow is the same, these viruses are not dramatic exceptions to the Central Dogma. By synthesizing a complementary strand that is used as a mold for other RNA strands, however, they demonstrate an interesting solution to the lack of an inherent template that double-stranded DNA normally provides.
Some RNA viruses use an enzyme called reverse transcriptase to synthesize DNA from an RNA template and actually reverse the normal flow of information.
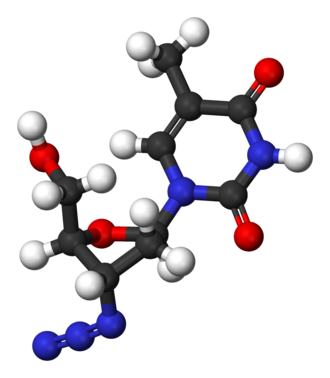
These retroviruses include HIV and certain tumor-producing viruses. When a retrovirus infects a host cell, the virus’s RNA is reverse transcribed into DNA that becomes incorporated into the host’s own DNA. The modified host DNA then serves as a template for synthesizing more viral RNA, which is translated into proteins. Retroviruses such as HIV are difficult to treat because they insert their material into the host’s DNA. The only cell functions that can be blocked or targeted are those specific to the virus. More general treatments will stop or impede the function of every cell in the body. Azidothymidine (AZT) resembles and is mistaken for thymine by reverse transcriptase (DNA polymerase does not often make the same mistake). When taken up by reverse transcriptase, AZT stops the polymerization of viral DNA. Reverse transcriptase is also prone to making errors in transcribed DNA; these errors allow retroviruses to evolve rapidly inside a patient. Evolution of the virus can then defeat the effectiveness of such treatments as AZT.
One key relationship of the Central Dogma has no exceptions as yet: Changes to proteins do not feed back to modify the information stored in RNA or DNA.
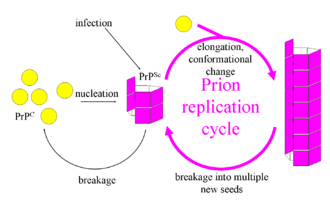
In one case, however, proteins seem to be able to modify other proteins. Prions (proteinaceous infective particles) are responsible for such diseases as mad cow disease, kuru, and other spongiform encephalopathies (“sponge brain diseases”). Prions are proteins that can apparently alter the shape of other proteins and, in so doing, destroy their function. In this sense, prions alter the information in other proteins, although the mechanism by which they do so is unclear. RNA acts only as an intermediate “messenger” in the Central Dogma, linking the information in DNA to the production of proteins.
END PART 9
BIOLOGY THE STUDY OF LIFE:
PART 1 INTRODUCTION
PART 2 WHAT IS LIFE
PART 3 ORIGIN OF LIFE
PART 4 CELL TO ORGANISM
PART 5 PROTEINS
PART 6 CODE OF LIFE
PART 7 DOUBLE HELIX
PART 8 REPLICATING DNA
PART 9 CENTRAL DOGMA

 or
or  @pjheinz
@pjheinzImage Credits:
ALL IMAGES UNLESS NOTED - Pixabay
CC0 Public Domain
Free for commercial use
No attribution required