机器学习这几年越来越火, 特别是相关算法五花八门, 但最有名的就那么几种, 而在这几种中, 要数KNN算法最为简单, 高效并且有鲁棒性 (Robustness).
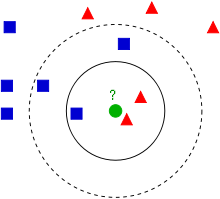
我们先来看一问题: 已知正方形和三角形的归类, 请问绿色的圆是属于三角还是属于正方形?
The K Nearest Neighbor (KNN) Algorithm is well known by its simplicity and robustness in the domain of data mining and machine learning. It is actually a method based on the statistics. It can be easily described as the following diagram.
// Image credited.
Known blue squares and red triangles, you are asked to predict if the green circle belongs to the squares or the triangles. If we choose K=3, then the minimal distances (closest) to the green circle are 2 triangles and 1 square, therefore, the circle belongs to the triangles. However, if we choose K=5, then we have 3 squares and 2 triangles, which will vote the cirlce to the squares group.
这里的KNN 指的是 K-nearest neighbour 翻译过来就是 K个最近的邻居, 如果我们指定K=3, 那么和绿色圆最近的是2个三角形和1个正方形, 所以按多数为主的标准, 我们预测这个圆属于三角, 相反, 如果K=5的情况, 和圆最近的有3个正方形和2个三角形, 这时候我们就按多数投正方形.
用 MYSQL 来演示 KNN算法 USING KNN AS PREDICTION ALGORITHM DEMONSTRATION BY MYSQL
我们先创建一个表含有两个字段x和y,
By the similar principle, KNN can be used to make predictions by averaging (or with weights by distance) the closest candidates. For example, if we have the following data (MySQL table test1):
mysql> select * from test1;
+------+------+
| x | y |
+------+------+
| 1 | 23 |
| 1.2 | 17 |
| 3.2 | 12 |
| 4 | 27 |
| 5.1 | 8 |
+------+------+
5 rows in set (0.04 sec)假设已知一个新点x=6.5, 我们想通过KNN (K=2)来预测y的值, 那么我们可以通过以下SQL语句来查找和6.5最近的两个点:
We want to predict when x=6.5, the value of y. First of all, for simplicity, we choose K=2, we need to find two points that have the shortest distance to 6.5, so the SQL will be:
mysql> select x,y from test1 order by abs(6.5-x) limit 2;
+------+------+
| x | y |
+------+------+
| 5.1 | 8 |
| 4 | 27 |
+------+------+
2 rows in set (0.00 sec)然后需要做的就是平均这两个点的y值, 用一个嵌套SQL语句就可以了:
Now, the task is just to average their corresponding y values. So using a nested SQL statement is trivial:
mysql> select avg(y) as predicted from (select y from test1 order by abs(6.5-x) limit 2) as KNN;
+-----------+
| predicted |
+-----------+
| 17.5 |
+-----------+
1 row in set (0.00 sec)KNN算法简单 但是有一个很大的问题是这个算法是属于 lazy 算法, 意思是拿到数据 (training set) 后并不是马上训练(甚至是并没有训练这个过程)而是等需要预测的时候实时去找最近的K个邻居, 所以当数据量大的时候 效率就比较低了.
KNN is lazy, meaning that it does not train dataset immediately (actually there is no training). When the input is given to the KNN model, it will look for K nearest neighbours at real time, which is slow and inefficient if the dataset is large.

Originally published at https://steemit.com Thank you for reading my post, feel free to FOLLOW and Upvote @justyy which motivates me to create more quality posts.
原创首发于 https://steemit.com 非常感谢阅读, 欢迎FOLLOW和Upvote @justyy 能激励我创作更多更好的内容. // 已同步到我的中文博客 和 英文算法博客。
近期热贴 Recent Popular Posts