在之前的文章《BUG? 个人主页无法读取到500篇以上内容》中,我们介绍了get_blog 方法,用于获取用户所有的文章。

(图源 :pixabay)
但是这个方法有一个弊端,受限于API节点max_feed_size的限制,无法读取某个用户近max_feed_size (默认500篇)以前的内容。
数据库方法 & 其它
在那篇文章中,我给出的建议是使用SteemSQL或者SteemData等数据库来获取用户所有文章,但是SteemSQL现在改成收费的了,SteemData的MongoDB 没接触过的朋友用起来可能不太方便,总之,使用数据库加大了操作难度。
那么,有没有其它API能用于获取指定用户的所有文章呢?其实STEEM API中好多是可以传入用户信息,然后用用户信息来进行过滤的,比如一堆get_discussions_by_XXX系列API,都是可以传入discussion_query结构来进行筛选的(最终调用get_discussions)

然而悲催的是,我从来没有试成功过。
get_discussions_by_author_before_date
数据库方法比较繁复,传入discussion_query的方法我一直没有尝试成功,难道就没辙了吗?
山重水复疑无路,柳暗花明又一村,所幸的是,我发现了get_discussions_by_author_before_date这个方法。
它接受的参数如下:
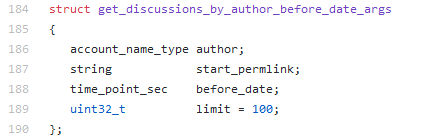
简单的来讲,这个函数获取指定作者(author)、指定链接(start_permlink)、指定时间点(before_date)以前的文章。
但是,这个方法有一些怪癖,导致我一度认为它行为不正常。
怪癖一
指定链接为空,指定时间点无效,返回用户最新文章列表(limit)
怪癖二
指定链接创建时间晚于指定时间点,那么两者都无效,返回用户最新文章列表(limit)
所以,正确的使用方式是,指定链接的创建时间早于指定时间点,返回早于指定时间点指定链接的文章列表(limit)。
有点拗口是吧,我们来实际演练一下。
我一年多前折腾过一个自动浇花装置
《基于Intel Edison自动浇花系统的最终报告/The automatic watering device with Intel Edison》
curl --data '{"jsonrpc": "2.0", "method": "call", "params": ["database_api", "get_discussions_by_author_before_date", ["oflyhigh", "intel-edison-the-automatic-watering-device-with-it-intel-edison", "2018-03-28T12:44:18", 2]], "id": 1}' https://api.steemit.com
那么上述指令就会返回我的自动浇花以及自动浇花之前的那篇文章。
(咦,这么说来好像时间点并没有起到什么作用,我们指定当前时间戳对应的时间点即可,莫非可能影响查询效率?)
接下来如何做?
知道了get_discussions_by_author_before_date怎么用,那么遍历文章还有什么难度吗?这篇文章就不再赘述啦。