This post was written bilingually, in English and Chinese. If you use the tool introduced in this post, you are able to read both languages!
本文用英文和中文写作,中文在后半部分。
Introduction
Background
Chinese characters are mysterious. You can more or less pronounce German, Italien or French words from their spellings even you know nothing of these languages because they are written in Latin letters, but you cannot pronounce Chinese characters from their looking. If you don't believe me, go to the cn category on steem and try. Chinese characters are not composed of Latin letters.
Fortunately, each Chinese character has a spelling in Latin letters, which is called pinyin. It is a must tool to learn Chinese. Here is the defination of pinyin on Wikipedia:
Pinyin, or Hànyǔ Pīnyīn, is the official romanization system for Standard Chinese in mainland China, Malaysia, Singapore, and Taiwan. It is often used to teach Standard Chinese, which is normally written using Chinese characters. The system includes four diacritics denoting tones. Pinyin without tone marks is used to spell Chinese names and words in languages written with the Latin alphabet, and also in certain computer input methods to enter Chinese characters.
The pinyin system was developed in the 1950s by many linguists, including Zhou Youguang, based on earlier forms of romanization of Chinese. It was published by the Chinese government in 1958 and revised several times. The International Organization for Standardization (ISO) adopted pinyin as an international standard in 1982, followed by the United Nations in 1986. The system was adopted as the official standard in Taiwan in 2009, where it is used for romanization alone (in part to make areas more English-friendly) rather than for educational and computer-input purposes.
If you want to learn Chinese, you have to start with pinyin. Chinese kids learn Chinese from pinyin. You can find the pinyin of each Chinese character in a dictionary. but would it be exciting if Chinese characters are converted to pinyin automatically?
Motivation
In my computer, many files are named in Chinese. When I want to share them with international friends, I have to convert the file names into Latin letters munally. If there are tens or hundreds of them, hmm, I would give up. What if they can automatically be done with R?
Some of my international friends are learning Chinese. When I share a nice Chinese post on Utopian.io with them, they complain that they have to look up the dictionary from time to time. The Chinese version of MS Word could help, but they have to copy and paste and adjust the layout and convert and so on. If there are multiple posts, they lose their patience. What if they can automatically be done with R?
Thus I developed an R package for converting Chinese characters into pinyin.
Powered with R language, you can do further statistics and analysis in Chinese pronunciations with the help of pinyin package!
Features
With R pinyin package, the tasks mentioned above can be achieved with one single command. Chinese characters can be converted into Latin letters in different ways, including the standard full spelling with or without the four tones, or the first letter of each character. You can convert either strings or text files, or rename multiple filenames.
Quick Start
Installation of R
Download R and install it.
Installation of pinyin
In R environment, run the following codes to install pinyin.
# stable version:
install.packages("pinyin")
# or development version:
devtools::install_github("pzhaonet/pinyin")
Examples
As an example, run:
library('pinyin')
pinyin('羌笛何须怨杨柳春风不度玉门关')
then you get the full spellings with Chinese tones as
## [1] "qiānɡ_dí_hé_xū_yuàn_yánɡ_liǔ_chūn_fēnɡ_bú_dù_yù_mén_ɡuān"
You can change the separators between the words:
pinyin('羌笛何须怨杨柳春风不度玉门关', sep = ' ')
## [1] "qiānɡ dí hé xū yuàn yánɡ liǔ chūn fēnɡ bú dù yù mén ɡuān"
You can use numbers to specify the tones:
pinyin('羌笛何须怨杨柳春风不度玉门关', sep = ' ', method = 'tone')
## [1] "qiang1 di2 he2 xu1 yuan4 yang2 liu3 chun1 feng1 bu2 du4 yu4 men2 guan1"
or toneless:
pinyin('羌笛何须怨杨柳春风不度玉门关', sep = ' ', method = 'toneless')
## [1] "qiang di he xu yuan yang liu chun feng bu du yu men guan"
or only the first letter of each word:
pinyin('羌笛何须怨杨柳春风不度玉门关', sep = '', only_first_letter = TRUE)
## [1] "qdhxyylcfbdymɡ"
The function file.rename2py()can convert Chinese file names into pinyin, and the function file2py() can convert text files into pinyin.
Now you can read Chinese articles aloud to your friends and shock them!
Link to the Repo
https://github.com/pzhaonet/pinyin
Proof of Work
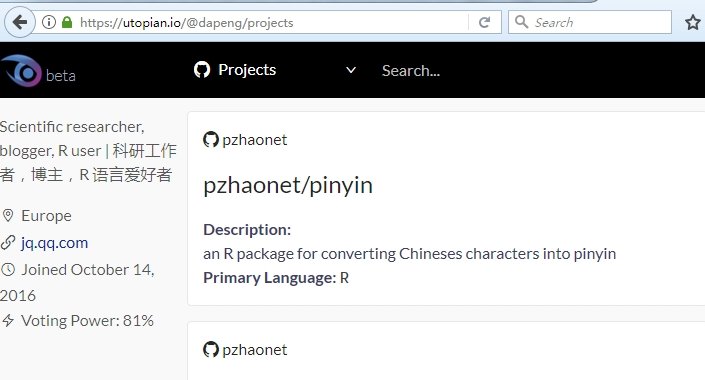
In my profile on Utopian.io, the github repo pinyin is listed in my project page, which is shown in the screenshot as follows:
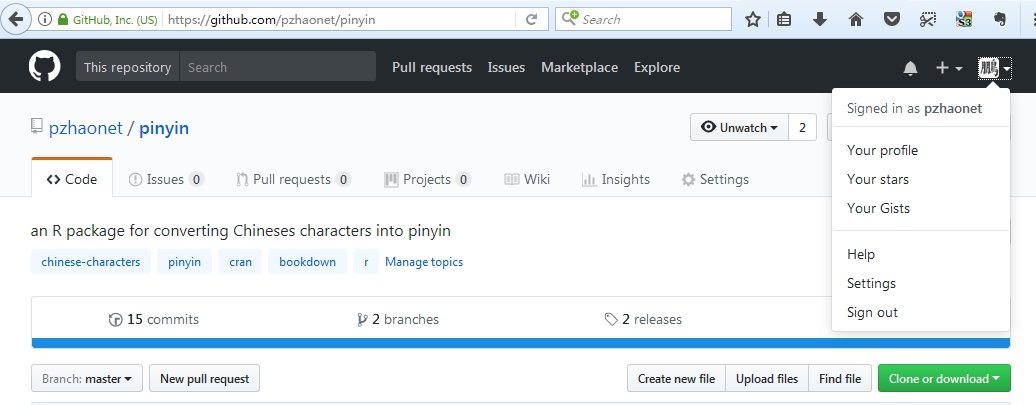
The login page on github.com is shown in the following screenshot:
我开发的这个 R 语言包,粗暴地用拼音取名为 pinyin,作用是把汉字转换成拼音。
有什么用呢?
有时候需要跟外国朋友分享我电脑里的一些文件,文件名是中文的,发过去人家看起来是乱码,所以我会先把文件名手动改成拉丁字母。文件少了还好,要是有成千上万个,算了,我不分享了。
中文在世界上的影响力愈来愈大,有些外国朋友在学中文。我是混 steem 的,看见好的中文帖想发给他们,他们抱怨说还得查字典。那就用中文版的 word 转换不行吗?拷贝,粘贴,调整格式,转换……烦死了。要是有多篇,算了人家没耐心弄了。
现在有了 R 语言的 pinyin 包,一条命令就能批量修改成千上万的文件名,能把多个字符串或多个文本文件转成拼音了。再说中文难学的老外,给我闭嘴。
而且,依靠 R 语言强大的数据处理、统计分析能力,你可以从 pinyin 包出发,对任何一篇文章的中文发音做文本分析了!
安装方法 [ān zhuānɡ fānɡ fǎ]
install.packages('pinyin')
# or
devtools::install_github("pzhaonet/pinyin")
函数 [hán shù]
pinyin 1.0.0版包含4个函数.pinyin()是主函数,可以把一个带汉字的字符串转换成拼音。可以选择:
- 转换成标准的全拼 (默认
method = 'quanpin'),或 - 以数字表示声调 (
method = 'tone') , 或 - 不含声调(
method = 'toneless'), - 也可以选择仅保留每个字的首字母(
only_first_letter = TRUE), - 可以自定义相邻两字拼音的分隔符号(
sep = '_'), - 如果汉字字符串里边包含非汉字字符,可以选择将这些字符保留原样(
nonezh_replace = NULL)还是转换成指定字符(如nonezh_replace = '-')。
其他函数是 pinyin() 的延伸和示例:
file.rename2py()用来对文件重命名,将文件名里的汉字转换成拼音。file2py()用来将指定文件夹里的一个或多个文本文件里的汉字全部转换成拼音。
Examples 示例 [shì lì]
以参数的默认值进行转换:
library('pinyin')
pinyin('羌笛何须怨杨柳春风不度玉门关')
## [1] "qiānɡ_dí_hé_xū_yuàn_yánɡ_liǔ_chūn_fēnɡ_bú_dù_yù_mén_ɡuān"
更改相邻拼音之间的分隔符号:
pinyin('羌笛何须怨杨柳春风不度玉门关', sep = ' ')
## [1] "qiānɡ dí hé xū yuàn yánɡ liǔ chūn fēnɡ bú dù yù mén ɡuān"
用数字表示声调:
pinyin('羌笛何须怨杨柳春风不度玉门关', sep = ' ', method = 'tone')
## [1] "qiang1 di2 he2 xu1 yuan4 yang2 liu3 chun1 feng1 bu2 du4 yu4 men2 guan1"
不使用声调:
pinyin('羌笛何须怨杨柳春风不度玉门关', sep = ' ', method = 'toneless')
## [1] "qiang di he xu yuan yang liu chun feng bu du yu men guan"
每个拼音只输出首字母:
pinyin('羌笛何须怨杨柳春风不度玉门关', sep = '', only_first_letter = TRUE)
## [1] "qdhxyylcfbdymɡ"
非汉字或汉语标点的字符保留原型:
pinyin('羌笛何须怨?杨柳春风,不度玉门关.', sep = '', nonezh_replace = NULL)
## [1] "qiānɡdíhéxūyuàn?yánɡliǔchūnfēnɡ,búdùyùménɡuān."
汉语标点符号会自动转换成对应的英文标点符号:
pinyin('羌笛何须怨?杨柳春风,不度玉门关。', sep = '', nonezh_replace = NULL)
## [1] "qiānɡdíhéxūyuàn?yánɡliǔchūnfēnɡ,búdùyùménɡuān."
如果自变量是多个字符串的向量,那么只会转换第一个字符串:
pinyin(c('羌笛何须怨杨柳', '春风不度玉门关'))
## [1] "qiānɡ_dí_hé_xū_yuàn_yánɡ_liǔ"
这怎么行?哎,用 sapply() 嘛:
sapply(c('羌笛何须怨杨柳', '春风不度玉门关'), pinyin)
## 羌笛何须怨杨柳 春风不度玉门关
## "qiānɡ_dí_hé_xū_yuàn_yánɡ_liǔ" "chūn_fēnɡ_bú_dù_yù_mén_ɡuān"
Posted on Utopian.io - Rewarding Open Source Contributors