Repository
https://github.com/BFuks/mad5-utopian-exercises
Introduction
I have attempted Exercise 1b in @lemouth's ongoing project (roadmap here) wherein we implement a Large Hadron Collider (LHC) particle physics analysis by modifying C++ code generated by their MadAnalysis5 toolkit.

(Image is a composite from (left-to-right) 1,2,3 respectively authored by by Energy.gov,Benjamin.doe, & OC and released under public domain, CC3, & CC3.
The specific goals of the exercise were to:
- identify baseline particles from a set of reconstructed detector events
- remove spurious particles from the identified baselines using a partial implementation of CERN's ATLAS overlap identification criteria.
Additional personal goals were:
- Re-familiarize myself with C++
- Specifically, learn how C11 differs from the last C flavor I coded in: pre-std, pre-boost VC++ 6.0
- Improve my efficiency in VIM
- Become comfortable with git branching, forking, tagging, and merging
Post main();
Exercise 1b was more challenging than Exercise 1a, which was the equivalent of 'Hello, world!' for this project. The challenge arose for three reasons.
- It required more domain knowledge of particle physics, including understanding a technical document which, to an outsider, was somewhat cryptic.
- The algorithm implemented required a moderate degree of care to implement. While no new data structures were required, it was more involved than looping through a vector and writing to the console. It also required some attention to detail to safely alter the existing data structures while iterating.
- I am extremely rusty with C and out of date on the current standards. I have been programming in essentially Python/R for the past 9 years, and my previous experience was on legacy code. Boost was just beginning to become popular the last time I touched C. The implications are that I had to remember a lot of lost knowledge about making the type system happy and had to play catch up on techniques such as the current idioms for filtering vectors.
To reflect on this experience, I'd like to organize this post around three topics; first discussing the physical system, followed by my implementation notes, and finally reflecting on how well I achieved both the exercise and my personal goals.
System analyzed
For those not familiar with it, MadAnalysis5 is a particle physics framework for analyzing reconstructed detector events. The workflow we've been following is to use MadAnalysis5 to generate C++ skeleton code which we then modify to analyze simulated LHC detector events from the Public Analysis Database (PAD), specifically the events described by this file.
As I understand it, the physics occurring within a detector cause events requiring the conditioning of raw signals. While @lemouth's given explanation is more canonical than mine, I will attempt to paraphrase to help myself understanding what's going on.
Essentially, collisions of non-elementary particles (such as photons) result in a morass of interactions. This morass is known as a jet and its physical properties give some clues as to what's going on.
What's important for this exercise is to know that not all jets are interesting and that multiple detected jets and other events can have the same 'fingerprint' and thus overlap. To handle the first case, we must generate a baseline list of interesting jets, muons, and electrons. To handle the second case, we must follow a specific order of criteria to 'weed out' overlapping baseline members.
Schematically, we are performing a sequential filtering on data, to arrive at the subset of signal particles illustrated below:
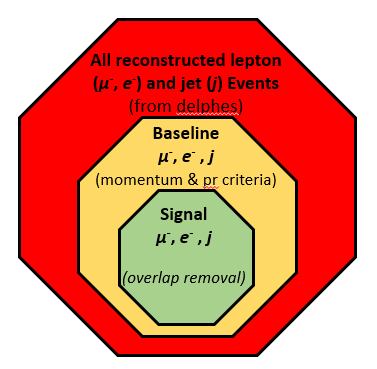
Sets and subsets of reconstructed events for this analysis. (Image my own, released under CC3) Baseline identification
The criteria for baseline identification of all three object types are based on threshold physical properties. Specifically, they must have both a transverse momentum above a minimum threshold and a pseudorapidity whose magnitude is below a maximum threshold. The values of those thresholds depend on the object type, as described in the CERN document and the exercise description. Beyond that, it is fairly easy to understand how to apply them, even without insight into why those criteria are useful or how the specific numbers are derived.
Overlap Removal
Although the actual calculation of overlap criteria is not particularly more complex than that for baseline identification (discipline-specific notation differences aside), overlap removal is more difficult to understand. Although I believe have more domain expertise would help, the major confounding factors were as follows:
- The combination of overlap criteria is a complex system. There are multiple steps, and each step consists of both a matching criterion and match condition.
- For this exercise, we are performing a partial implementation. This simplifies some aspects, but it also introduces ambiguity.
- The document itself can be hard to parse (beyond particle physics jargon). As examples, the CERN doc refers to a 'matching requirement', yet the the criteria table (Table 3, p. 15 of the CERN doc) only has 'criteria' and 'condition', leading to some ambiguity. There are other issues as well with the text, but I don't believe it is the authors' fault. Any textual description of these criteria, even with a table, is essentially problematic. More concrete examples, or better yet, a reference implementation, would help. The figure below is my flowchart used to figure out what I believe the correct approach should be for this exercise.
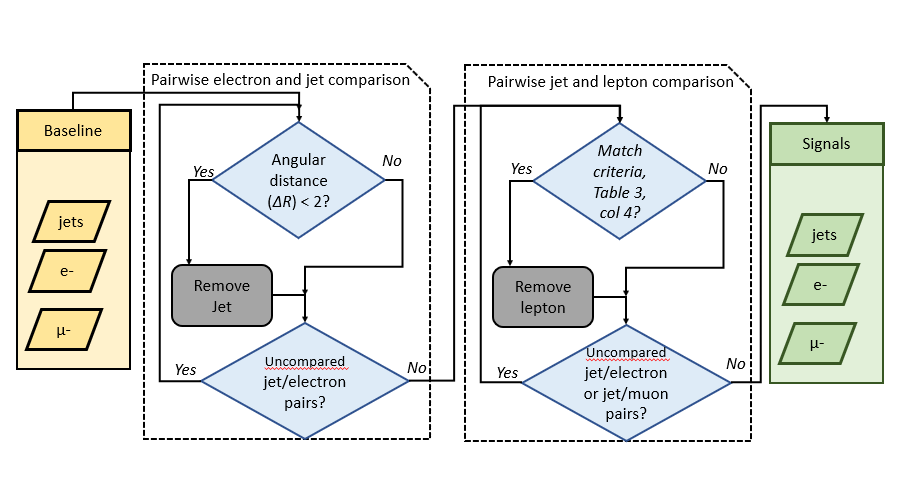
Logical flow of partial overlap removal for this analysis. (Image my own, released under CC3) Implementation
Because of the challenges I faced understanding overlap removal, I decided to perform the implementation in two steps. First, I wanted to get the overlap removal implemented. Then, and only then, would I worry about modifying the implementation to use modern C++ or refactoring.
First step (Overlap Removal)
It required a few trials to get the overlap removal to a point where I was was satisfied that it was probably correct, and if not correct, then understandably wrong. The code consists of old-style for loops over indices into vectors, with this snippet being representative:
vector<RecLeptonFormat> baseLineElecs; // Looking through the reconstructed electron collection for (MAuint32 i=0;i<event.rec()->electrons().size();i++) { const RecLeptonFormat& elec = event.rec()->electrons()[i]; const double momentumBound = 5; //GeV const double psuedoRapidityBound = 2.47; if(momentumBound < elec.pt() && psuedoRapidityBound > abs(elec.eta())){ baseLineElecs.push_back(elec); } }The major issues with this implementation were, as expected, that it didn't take advantage of modern vector operations or refactoring. This lead to it being verbose and brittle. Most of the logic was also tied up in managing details, like indices and safe removal, rather than the 'business logic', making it hard to grasp the code's intentions. The commit which best represents this stage is in my personal repository here.
Second attempt (modern C++)
At its heart, this exercise is essentially generating a few vectors and filtering them based on various criteria. Using the operations made available by C++11 really helped abstract away many implementation details, making the code much more intentional. For example, the above snippet can be extracted into a method:
void test_analysis::filterBaseLine(const vector<RecLeptonFormat> &from, vector<RecLeptonFormat> &to, double min_pt, double maxAbsEta){ copy_if(from.begin(),from.end(), back_inserter(to), [&min_pt,&maxAbsEta](const RecLeptonFormat& l){return (l.pt() > min_pt ) && (abs(l.eta())< maxAbsEta);}); }and the entire baseline filtering portion becomes:
/*************************************************** * Create baseline vectors ***************************************************/ filterBaseLine(event.rec()->electrons(),elecs,5,2.47); filterBaseLine(event.rec()->muons(),muons,4,2.7); filterBaseLine(event.rec()->jets(),jets,25,2.5);Similar benefits were realized with the overlap removal code. Further safety was insured by using the built in
remove_ifalgorithm, rather than managing vector indices. The full version of my code, after the pull request, can be viewed at the main repository (asex1b-effofex.*) and also on the task 1b branch of my personal repository.This is the relevant output from my current version:
=> progress: [===> ] Base and signal vector sizes Particle Base Removed Signal Jets: 5 0 5 Elecs: 0 0 0 Muons: 0 0 0 => progress: [======> ] Base and signal vector sizes Particle Base Removed Signal Jets: 6 0 6 Elecs: 0 0 0 Muons: 0 0 0 => progress: [==========> ] Base and signal vector sizes Particle Base Removed Signal Jets: 8 8 0 Elecs: 2 0 2 Muons: 1 0 1 => progress: [=============> ] Base and signal vector sizes Particle Base Removed Signal Jets: 8 0 8 Elecs: 0 0 0 Muons: 1 1 0 => progress: [=================> ] Base and signal vector sizes Particle Base Removed Signal Jets: 7 0 7 Elecs: 0 0 0 Muons: 0 0 0 => progress: [====================> ] Base and signal vector sizes Particle Base Removed Signal Jets: 6 0 6 Elecs: 0 0 0 Muons: 1 1 0 => progress: [========================> ] Base and signal vector sizes Particle Base Removed Signal Jets: 4 0 4 Elecs: 0 0 0 Muons: 0 0 0 => progress: [===========================> ] Base and signal vector sizes Particle Base Removed Signal Jets: 6 6 0 Elecs: 1 0 1 Muons: 0 0 0 => progress: [===============================> ] Base and signal vector sizes Particle Base Removed Signal Jets: 8 0 8 Elecs: 0 0 0 Muons: 0 0 0 => progress: [==================================>] Base and signal vector sizes Particle Base Removed Signal Jets: 7 7 0 Elecs: 1 0 1 Muons: 0 0 0 => progress: [===================================]Goal analysis
I'd like to reflect briefly on the degree to which I achieved the goals for this exercise.
Identify baseline particles from a set of reconstructed detector events
I believe that I'm doing this correctly. It was a good entry into the event record data structures and helped me brush the cobwebs off some basic C++ syntax issues.
Overlap removal
I don't know if I did this correctly. I think my approach makes sense, at the very least, I do think it was intelligible enough for @lemouth to tell me what went wrong if there was an error.
Relearning C++
This was a big goal for me. I'd forgotten how different it is to program in a more strictly typed, compiled system, after coming from lots of Python and R. While I don't think I'll ever enjoy managing header files, I do have to say that C++11 was refreshing. I had a vague idea that iteration through vectors was going to be nicer than I'd remembered, but I was unaware of how much the syntax has improved - especially the
autokeyword and the ability to use lambda functions. Although the documentation on some of these was still closer to a man page than a tutorial, it wasn't too rough to learn from.By far, the bigger obstacle was in remembering things I'd forgotten - both explicit memory management and casting/polymorphism come to mind. In fact, you might notice that I avoided doing anything too ambitious with passing references to vectors around or taking advantage of
RecParticleFormat, the base to the two major classes used in the code, to remove some code duplication. I decided not to pursue those right now so that I'd finish in time. It is also for those reasons that I decided to not pursue unit testing, although I was happy to see thatcppunitis still around.VIM and git goals
I've used VIM a bit, but not much and realized that since I'm running this software in non-gui Unix environment (specifically the Windows 10 WSL ), that this would be a good time to brush up. After shaking some cobwebs out, I'm fairly comfortable doing basic navigation and editing tasks. I'm getting better at doing multi-line yanking instead of retyping and have flirted a bit with regexen and multiple buffers. The biggest issue is reflexively hitting Ctrl-Z to undo - this kicks me out of VIM and creates a .swp file. I plan on checking out some vim interactive tutorials 1, 2 and also the vim adventures game in a bit to practice.
I've used git for a long time, but almost exclusively for solo projects. Basically, lots of commits on a single branch. This has forced me to get, if not comfortable with, at least exposed to using branches to track my progress on exercises and better understanding forkss, pull requests, origins, and such for working with multiple people.
Resources
A note on repositories
Because this series features a set of exercises on code generated by another code base, there's a few layers of repositories.
- The canonical base for the completed exercises is maintained by @lemouth
- I maintain my own fork with code to be pulled into the main repo
- I keep a 'working directory' with the full generated codebase, separated by branches for each exercise, such as the 1b branch
- MadAnalysis5 itself is kept on launchpad, as that's what most people working in that discipline are used to, but @lemouth has mirrored it on Github
Useful C++ stuff
- Wikepedia article on changes to C++ since I last used it
- I found cppreference to be particularly useful
VIM stuff
- Why bother
- Vim adventures
- Online interactive tutorials 1, 2
Documentation
- CERN ATLAS detector reference pdf
- MadAnalysis5 Sample Analyzer code documentation
- MadAnalysis5 main site
Series Backlinks
As I understand it, this section is mainly for links within my own series contributions. Below that list, I will also include the relevant links to other's posts within this series.
- Installing MadAnalysis5 under WSL and Task1a
- Further exercises to follow
- Specifically, learn how C11 differs from the last C flavor I coded in: pre-std, pre-boost VC++ 6.0