
I know things are looking stale on the Gridcoin development side, but we have been working to add stability to the wallet and are now in the final test phase of Gridcoin 3.7.0.0 which will be a mandatory upgrade. There is no set release date yet other than as there are two more changes I want to include and test to further improve the forking situation when reorganizing. When released we will set a V9 trigger height roughly 2 weeks beyond release date to give exchanges time to react. After that the fork fixes will kick in and we can start removing the obsolete tally code.
While there are many, many more features and fixes done, I will try to cover some of the larger ones. Please see closed github pull requests for a hard to read but complete list.
TL;DR:
- The chain should now fork less often.
- Windows clients will hopefully freeze less.
- Nodes should sync faster.
- The wallet should use a little less CPU.
Fork improvements
We have had a lot of problems with wallets disagreeing on rewards and taking different routes on the chain. That is, different forks. We believe that the reason for this is that wallets have different views on how much each user is owed due to the way the nodes collect historical rewards and magnitudes. V9 blocks introduced in version 3.7.0.0 change this with two important fixes:
- Rewards are now validated when connecting the block to the chain instead of when the block is received to avoid future blocks not matching tallies.
- Reward tallies are now done in a more deterministic and synchronized way whereas it previously was initially done in sync but was easily disturbed.
These changes solve two very fork happy and hard to debug issues. The caveat is that it may not solve all fork issues, just the ones we have managed to track down.
Improved syncing
Gridcoin has a mechanism which allows clients to request blocks in bursts to improve the synchronization speed. Roughly speaking, the nodes sending block metadata will save information about the last block information sent to the syncing node, making that block a sentry. Whenever the syncing client requests the sentry block another burst of block metadata is sent along with it.
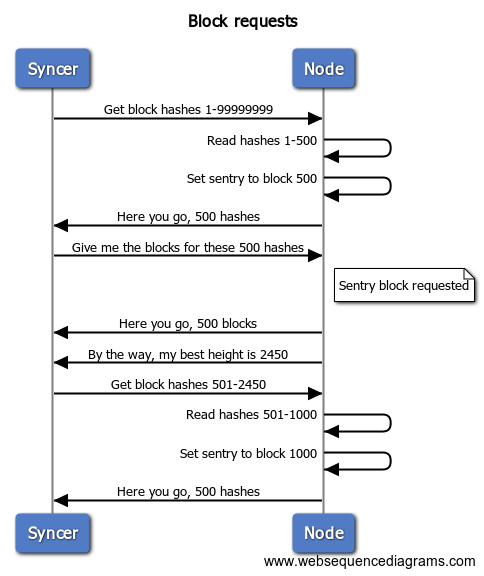
This repeats until the the syncer stops requesting blocks or until the node does not have any more blocks to send. Note: Image is not entirely true as the communication is done with hashes, not heights. The basic flow still applies.
A while ago this block burst size was changed from 500 to 1000 blocks which caused the burst size to exceed the maximum allowed transmission size, so the syncing node never got information about the sentry block. You would see that as hickups in the chain synchronization. Your node would receive a burst of blocks, pause for a long time, receive the next burst and so on. The pause bug is fixed and the pauses are now only when the remote end loads its blocks from disk.
Deadlocks
This is going to be a bit technical but I'll try to explain it as well as I can.
In computer programming it is often beneficial to do things in parallel to avoid making the program feel sluggish. For example, you do not want the user interface to freeze while the program is processing a burst of received blocks. The easiest way to solve this is to use threads. This also has the benefit of utilizing more cores on the CPU. However, using threads is not free. Since there are now multiple data produces and consumers you have to make sure that they are not manipulating data simultaneously. The way you solve this is by using locks.
Each thread which wants to read or write shared data will have to wait for a lock to be released before they can acquire it themselves. One single lock won't bring down a software on its own. The devious behavior come when you have multiple locks and aquire the locks in different order.
In Gridcoin we use a lot of locks for protecting various different resources. In one recent issue two particular locks, cs_Main and cs_vSend were involved in threads aquiring them in different order. Even though there is a very small risk that the threads deadlock, the order has now been changed so the deadlock problem in this case is eliminated.
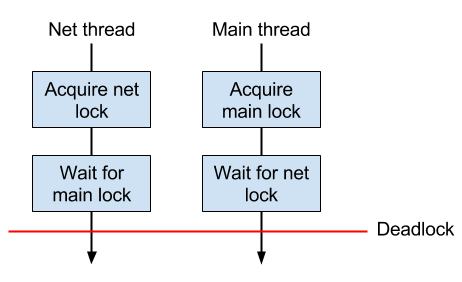
If we are right about this deadlock it would explain why Windows wallets are more prone to running into this issue than Linux wallets. The reason is that Windows wallets hold the cs_Main lock while performing NeuralNet operations before they also take the cs_vSend lock. Since the NeuralNet operation can take several seconds they are way more likely to deadlock. The way this manifests itself is a user interface freeze.
Note that since we have not been able to reproduce the Windows freezes in a debugger it is very likely that the problem remains. Only time will tell. Threading and locks are tricky business at this source magnitude so we cannot assure that all the deadlocks are gone, but it should at least be better now.
Crashes
Windows users have been plagued with silent shutdowns for a while now. We tracked down a very likely cause to where the NeuralNet started scraping the BOINC statistics data while a scaping operation was already in progress. The first thing the scraper does is to delete the currently downloaded statistic files. In this case the files were obliterated right under the feet of the first scrape operation, casuing it to lay down and die.
We now block concurrent stat syncing and gracefully handle file I/O errors.
Performance improvements
A lot has been done to improve the overall performance of the wallet. Existing code has been tweaked and optimized while some obsolete code has been removed, opening up for further improvements.
Data structures
Following changes in the Bitcoin base we have changed the underlying data structure holding blocks to a more efficient one. This will consume around 1-1.5% more memory but every time we access a block in the existing chain we save a good amount of CPU cycles. This will especially affect chain loading but the improvement ripples throughout the entire code base.
To put some numbers to it, after syncing the chain on a Raspberry Pi 3 the old implementation spent 46% of the total execution time querying the chain for blocks. This is now down to 13%.
Checkpoints
We previously had mechanisms for relaying checkpoints between nodes. This was not needed as checkpoints are hard coded in the client, something that is good enough for its purpose. By removing the relaying we could greatly simplify the checkpoint validations which will cause the nodes to use a lot less CPU when processing blocks. This is especially noticeble when synchronizing the chain, something which should be a lot faster now.
String conversions
The code responsible for converting floating point values to and from strings has been greatly simplified and gained a large performance boost. As in the previous sync test on the Pi3, we did 22 million calls to cdbl (round a double contained in a string), spending 18% of the total execution time. Unfortunately I didn't keep the aftermath numbers, but it is much, much better now.
Post 3.7.0.0
Many of you are probably wondering where the heck the rebranding changes have gone. Don't worry, we intentinally postponed the UI changes in favor of focusing on only the stability. The rebranding will be done in 3.7.1.0 as a leisure update.
Posted on Utopian.io - Rewarding Open Source Contributors