
CN-Malaysia bot has been setup for 2 months, you can check the initial post where I shared about the aim of the bot. Since the release of the bot, there is a few complaints about it, so I managed to patch it and complete rewrite the whole project into TypeScript with dsteem library and added Testing with Jest.
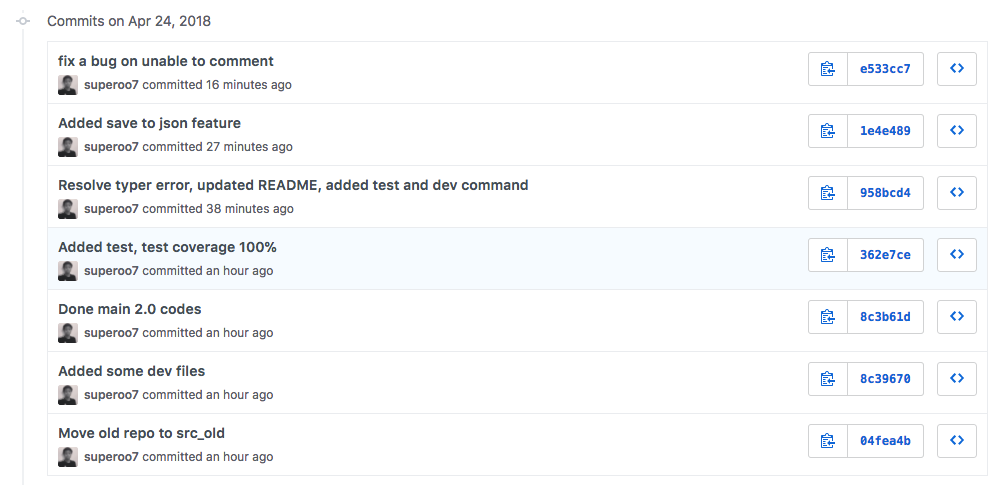
Commit History
Bug Fixes
What was the issue(s)?
- [1] Duplicate similar comment because the bot watch for changes in post on Steem Blockchain.
- [2] No whitelist feature
What was the solution?
- [1] Create a json file called
data.jsonto stored links that has been commented by the bot - [2] Whitelist feature added into
config.ts[link on github]
- [1] Create a json file called
New Features
What feature(s) did you add?
How did you implement it/them?
- Since dsteem is written in TypeScript, dealing with Steem API is cleaner and easier, however there is still a feature of SteemJS being used, which is
steem.api.getContentAsync(), since dsteem does not have this feature, will use steemjs for this one. - Testing is essential for the project to be scalable and easy to be develop. Jest is used in the bot.
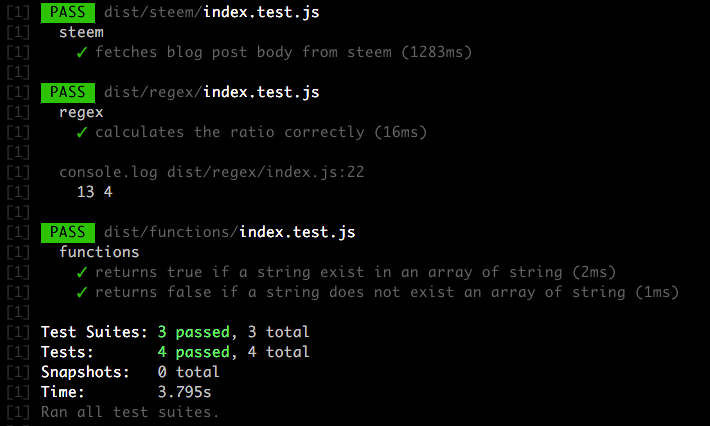
- TypeScript offers compile time type check and helps a lot in the development progress in future.
- Since dsteem is written in TypeScript, dealing with Steem API is cleaner and easier, however there is still a feature of SteemJS being used, which is
Link to relevant lines in the code on GitHub and explain briefly what you added/changed.
About this Projects
- What is the project about?
#cn-malaysia is a tag for the chinese community in Malaysia. The aim is to get user to post quality chinese content. One of the issue sometimes is that people misunderstood about this tag and start to use it with posts that are not related to chinese content.
Before the creation of the bot, me and @davidke20 are manually checking and advise the user that used #cn-malaysia without containing chinese content to not use this tag.
- Technology Stack
TypeScript, Node.js, Jest, dsteem, steem-js
Roadmap
- Added test to add json file
- Update API when dsteem released a more suitable one
- Regex to parse out data from table from markdown, to correctly calculate the percentage of chinese words to english words.
How to contribute?
GitHub link
This project is on GitHub with MIT License, feel free to send in Pull Request or Issue Filling.
Posted on Utopian.io - Rewarding Open Source Contributors