
안녕하세요. @mishana입니다. #kr-dev 첫 글을 올립니다. 🎉
"이 스팀잇의 RSS 피드를 지원합니다"에서는 제목 그대로 이 스팀잇의 RSS 피드를 공개하였습니다. 서브 도메인 https://rss.mishana.kr/ 하나를 통째로 이 블로그의 RSS로 사용하고 있습니다.
이 글에서는 스팀잇의 RSS를 만들었던 기본 아이디어와 구현 방법을 공유해볼까 합니다.
RSS는 Rich Site Summary의 줄임말로 사이트의 갱신 사항을 전달하기 위한 포맷입니다. RSS 피드 주소에 직접 들어가보시면 아시겠지만 이 페이지는 사람이 직접 보기 위한 페이지는 아닙니다. 일반적으로 RSS 리더와 같은 애플리케이션에 해당 주소를 추가해두면, 새로운 글이 올라왔을 때 RSS 리더에도 글이 업데이트 됩니다. RSS는 10년 전만해도 블로그의 부흥과 함께 새로운 정보 구독 방식으로 각광 받았습니다만, SNS가 보편화된 지금은 구시대의 유물 같은 존재가 되어버렸습니다.
그나마 Feedly와 같은 온라인 RSS 리더나 몇 가지 애플리케이션 들이 명맥을 유지하고 있는 정도입니다. 스팀잇 저장소에도 몇 년 전에 RSS 피드에 대한 이슈가 올라와있지만 아직은 개발이 진행되지 않고 있는 상황입니다.
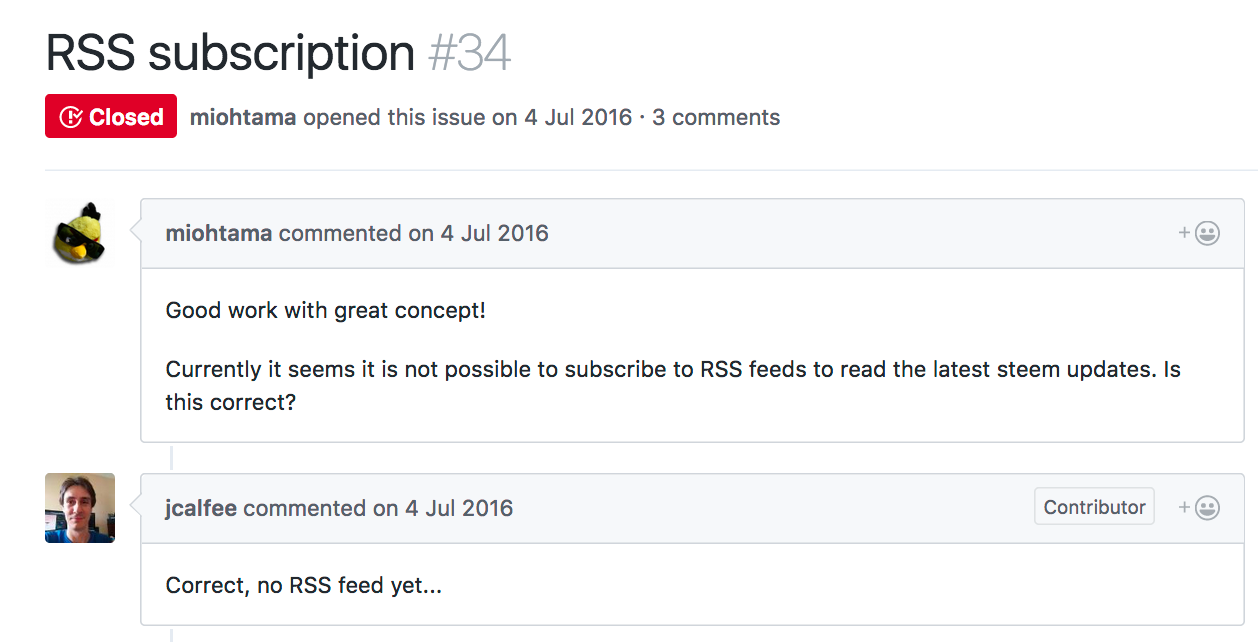
언젠가 스팀잇에서 직접 RSS 피드를 지원해줄 것 같지만 언제가 될지는 알 수 없습니다. 스트리미안(Streemian)에서도 RSS 서비스를 제공하고 있지만 저자의 타임라인 전체가 RSS로 만들어지고, 본문이 마크다운 소스코드로 출력되는 등 몇 가지 문제점이 있었습니다. 🤔

그마저도 며칠 전부터는 작동하지 않고 있는 듯 합니다. 😞
저는 블로그하면 RSS가 떠오르는 부류의 올드한 마인드를 가진 사람이라서 플랫폼에서 지원해주지 않으니 직접 만들어보기로 했습니다.
radiator로 스팀잇 데이터 가져오기
저는 주로 개인 프로젝트에서는 루비(Ruby) 프로그래밍 언어를 사용하고 있습니다. 언어 소개나 개발 환경 구축에 대한 이야기는 여기서는 생략하도록 하겠습니다.
루비에도 스팀잇을 지원하는 라이브러리가 radiator라는 이름으로 공개되어 있습니다. 루비의 패키지 관리자로 이 라이브러리를 설치할 수 있습니다.
$ gem install radiator
radiator를 사용해 데이터를 불러오는 건 아주 간단합니다. radiator 클래스의 객체를 생성후 steemit의 API 명령어를 호출해주면 됩니다. 다음 예제에서는 get_discussions_by_blog API를 사용해 이 블로그의 최신 글들을 불러와 보겠습니다. 테스트 용도이므로 인터렉티브 쉘에서 간단히 진행해보겠습니다.
$ irb
> require 'radiator'
> option = {tag: 'mishana', limit: 3}
> posts = Radiator::Api.new.get_discussions_by_blog(option)['result']
option 해시에는 tag와 limit을 지정할 수 있습니다. get_discussions_by_blog에서 tag 옵션은 사용자를 지정하는 용도로 사용됩니다. limit에는 몇 개의 글을 불러올지 지정합니다.
get_discussions_by_blog에서 불러온 해시를 반환하고, 이 해시의 "result" 키에 데이터 배열이 저장됩니다. 이 배열에 있는 데이터는 하나하나가 스팀잇의 글이 담겨있습니다. 글마다 다음과 같은 키(데이터)를 가지고 있습니다.
> posts[0].keys
["id", "author", "permlink", "category", "parent_author", "parent_permlink", "title", "body", "json_metadata", "last_update", "created", "active", "last_payout", "depth", "children", "net_rshares", "abs_rshares", "vote_rshares", "children_abs_rshares", "cashout_time", "max_cashout_time", "total_vote_weight", "reward_weight", "total_payout_value", "curator_payout_value", "author_rewards", "net_votes", "root_comment", "max_accepted_payout", "percent_steem_dollars", "allow_replies", "allow_votes", "allow_curation_rewards", "beneficiaries", "url", "root_title", "pending_payout_value", "total_pending_payout_value", "active_votes", "replies", "author_reputation", "promoted", "body_length", "reblogged_by"]
다양한 데이터가 있는 것을 알 수 있습니다. author, url, body, title 등 대부분의 속성은 의미를 유추할 수 있지만 아직 모든 속성을 파악하진 못 했습니다. 하지만 기본적인 것만 알아도 RSS를 만들기에는 충분해보이므로 간단히 데이터를 확인해봅니다.
> posts[0]["author"]
=> "mishana"
> posts[0]["body"][100..200]
=> "\n\n안녕하세요. @mishana입니다.\n\n트위터와 스팀잇에서 본격적으로 Mishana라는 이름을 사용하기 시작하면서, [개인 도메인](https://mishana.kr)을 만들어보았"
> posts[0]["url"]
=> "/kr/@mishana/rss"
이 내용을 통해서 이 글을 작성하는 시점에 가장 최근에 올린 RSS 피드 지원 공지 글을 가져왔다는 것을 알 수 있습니다. 정말 간단하죠?
이제 이 데이터들을 사용해서 바로 RSS를 만들면 될 것 같지만, 그에 앞서 몇 가지 전처리를 해보겠습니다.
전처리 1단계: 데이터 필터링
RSS의 데이터로 사용하기에 get_discussions_by_blog API에는 한 가지 문제가 있습니다. 직접 눈으로 확인해보겠습니다.
> posts[1]["author"]
=> "julianpark"
> posts[1]["title"]
=> "새롭게 돌아온 치킨장학금 3회차 결과 + 공지사항"
분명히 tag를 mishana로 지정했는데 두 번째 글은 @julianpark 님의 치킨장학금 글이 나오는 것을 확인할 수 있습니다. 무슨 일이 벌어진 걸까요?
get_discussions_by_blog API는 블로그의 글만 불러오는 것이 아니라 해당하는 저자의 타임라인을 불러오기 때문입니다. 따라서 저자가 리스팀했던 글도 목록에 포함이 됩니다. 타임라인 RSS를 만드는 경우라면 상관이 없지만, 블로그의 RSS를 만드려면 리스팀한 내용을 제외시켜야합니다.
steemit/steem 저장소의 이슈를 찾아보면 코드 상에는 2016년에 hide 옵션이 추가되서 리스팀한 내용을 숨길 수 있는 기능이 있었습니다. hide: resteemed와 같이 옵션을 지정할 수 있었는데, 아쉽게도 현재 작동하지 않습니다. 정확한 경위는 파악하지 못 했는데 현재는 이 코드가 제외된 듯 합니다. 따라서 지정한 저자가 작성한 글만 가져오려면 타임라인을 불러온 다음에 필터링을 해야합니다.
리스팀을 제외할 것이기 때문에 RSS에서 제공하고자 하는 글 수보다 넉넉하게 글을 불러와야합니다. 정확한 갯수를 보장하려면 좀 더 궁리가 필요한 데 여기서는 일단 단순히 리스팀한 글만 제외시켜보겠습니다.
이번에는 20개의 글을 불러오겠습니다.
> author = 'mishana'
> option = {tag: author, limit: 20}
> posts = Radiator::Api.new.get_discussions_by_blog(option)['result']
posts 변수는 배열 데이터이므로 .select 메서드를 사용해 필터링합니다. 다음 코드는 posts 배열에서 author 속성이 mishana인 값만을 남깁니다. 이 배열을 mishana_posts에 대입합니다.
> mishana_posts = posts.select &->(post){post['author'] == author}
데이터가 잘 필터링 되었는지 확인해봅니다.
> mishana_posts.length
=> 6
[24] pry(main)> mishana_posts.map &->(post){ post.author }
=> ["mishana", "mishana", "mishana", "mishana", "mishana", "mishana"]
20개에서 14개의 리스팀된 글이 제외되고 6개만이 남았습니다. 남아있는 모든 글의 author도 확인해봤습니다. 현재 남아있는 모든 글의 저자가 mishana인 것을 확인할 수 있습니다.
전처리 2단계: 본문 마크다운 렌더링
전처리 두 번째 단계는 본문 처리입니다. 스팀잇에서는 마크다운을 지원하고 있으며, 마크다운 소스가 그대로 스팀잇에 저장됩니다. 따라서 글의 body 데이터로 RSS를 만들어 버리면 RSS 리더에서 HTML 렌더링 된 컨텐츠가 아니라 마크다운 소스코드가 노출되어 버립니다. 이미지도 안 보이고, 문단도 엉망이 되어버립니다. 이러한 문제를 방지하기 위해서는 body의 내용을 미리 마크다운 렌더러로 HTML 렌더링한 다음에 이 내용을 피드에서 사용할 필요가 있습니다.
루비로 구현된 마크다운 라이브러리는 몇 가지가 있습니다. 이 예제에서는 마크다운 렌더러로 redcarpet을 사용해보겠습니다. 먼저 설치를 해야합니다.
$ gem install redcarpet
사용법은 간단합니다. HTML 렌더러를 생성하고, 이 렌더러로 마크다운 렌더러 객체를 생성합니다. 그래고 .render 메서드에 본문을 넘겨주면 됩니다.
> renderer = Redcarpet::Render::HTML.new(render_options = {})
> redcarpet = Redcarpet::Markdown.new(renderer, extensions = {})
> redcarpet.render(mishana_posts[0]['body'])
일부 텍스트에 대해서 변환되는 내용을 확인해보겠습니다.
\n\n안녕하세요. @mishana입니다.\n\n트위터와 스팀잇에서 본격적으로 Mishana라는 이름을 사용하기 시작하면서, [개인 도메인](https://mishana.kr)을 만들어보았습니다.
마크다운으로 작성된 이 내용이 다음과 같이 HTML로 변환됩니다.
<p><img src="<img class="markdown-img-link" src="https://steemitimages.com/0x0/https://res.cloudinary.com/hpiynhbhq/image/upload/v1515162727/ck8oiu9387edeztkevrd.png""/> alt="image.png"></p>\n\n안녕하세요. @mishana입니다.p>\n\n<p>트위터와 스팀잇에서 본격적으로 Mishana라는 이름을 사용하기 시작하면서, <a href="https://mishana.kr">개인 도메인</a>을 만들어보았습니다.
이제 RSS 피드에서도 문제 없이 읽을 수 있을 것 같습니다!
RSS 모듈로 RSS 생성하기
마지막 단계입니다. 지금까지 준비한 데이터를 RSS 포맷으로 만들어야합니다. 루비에 기본적으로 포함되어있는 RSS 라이브러리로 만들어보았습니다. RSS의 자세한 사용법은 문서에서 확인할 수 있습니다.
다음 코드로 RSS를 만들었습니다.
require 'rss'
require 'radiator'
require 'redcarpet'
author = 'mishana'
option = {tag: author, limit: 20}
posts = Radiator::Api.new.get_discussions_by_blog(option)['result']
author_posts = posts.select &->(post){post['author'] == author}
renderer = Redcarpet::Render::HTML.new(render_options = {})
redcarpet = Redcarpet::Markdown.new(renderer, extensions = {})
rss = RSS::Maker.make("2.0") do |feed|
feed.channel.title = "#{author}'s Steemit"
feed.channel.link = "https://steemit.com/@#{author}"
feed.channel.about = "" # 이 RSS 피드가 제공되는 URL을 지정
feed.channel.description = "RSS feed of #{author}'s Steemit"
feed.channel.updated = Time.now
feed.channel.author = "#{author}"
author_posts.each do |post|
feed.items.new_item do |item|
metadata = JSON.parse(post["json_metadata"])
item.title = post.fetch('title')
if metadata.fetch('format', nil) == 'markdown'
body = redcarpet.render(post.fetch('body'))
else
body = post.fetch('body')
end
item.description = body
item.link = "https://steemit.com#{post.fetch('url')}"
item.author = post.fetch('author')
item.date = post.fetch('created')
metadata.fetch('tags').each do |category_content|
item.categories.new_category do |category|
category.content = category_content
end
end
end
end
end
puts rss
feed.channel.about에는 이 RSS가 실제로 제공되는 주소를 지정해야합니다.
이 내용을 rss.rb에 저장하고 실행해보면 다음과 같이 텍스트로 출력되는 것을 확인할 수 있습니다.
$ ruby rss.rb
<?xml version="1.0" encoding="UTF-8"?>
<rss version="2.0"
xmlns:content="http://purl.org/rss/1.0/modules/content/"
xmlns:dc="http://purl.org/dc/elements/1.1/"
xmlns:itunes="http://www.itunes.com/dtds/podcast-1.0.dtd"
xmlns:trackback="http://madskills.com/public/xml/rss/module/trackback/">
<channel>
<title>mishana's Steemit
https://steemit.com/@mishana
RSS feed of mishana's Steemit</description>
<pubDate>Tue, 09 Jan 2018 10:57:23 +0900</pubDate>
<item>
<title><공지> 이 스팀잇의 RSS 피드를 지원합니다</title>
...
<dc:date>2018-01-09T10:57:23.500818+09:00</dc:date>
</channel>
</rss>
정상적으로 RSS가 만들어진 것을 알 수 있습니다!
태그 데이터 필터링
여기까지 개인 블로그 피드를 만드는 방법을 알아보았습니다. 그렇다면 태그에 올라오는 글들을 RSS 피드로 만들 수도 있지 않을까요? 아래 3가지 API를 사용하면 특정 태그에 올라오는 글들을 get_discussions_by_blog와 마찬가지 형식으로 가져올 수 있습니다.
radiator.get_discussions_by_created: 최신글radiator.get_discussions_by_trending: 트렌딩radiator.get_discussions_by_hot: 인기글
사용법은 get_discussions_by_blog 메서드와 기본적으로 똑같습니다. 다음 코드는 kr 태그에서 가장 최근에 올라온 글 100개를 가져옵니다.
> tag = 'kr'
> option = {tag: tag, limit: 100}
> posts = Radiator::Api.new.radiator.get_discussions_by_created(option)['result']
이 데이터를 사용하면 태그의 최신 글 RSS를 만들 수 있을 것입니다. 조금 더 가공해볼 수도 있습니다. 예를 들어 본문 길이가 5000자 이상인 글들만 필터링한다면 이 데이터를 body_length 키로 다시 한 번 필터링을 하면 됩니다.
posts.select &->(post){post['body_length'] > 5000}
이 데이터를 사용하면 특정 태그의 일정 길이 이상으로 작성된 글들로 RSS를 만드는 것도 가능합니다.
마치며
여기까지 루비로 간단하게 스팀잇 데이터를 가져와 RSS를 생성해보았습니다. 실제로 RSS를 지속적으로 제공하려면 여기서 끝나는 것은 아닙니다. 이 내용을 매번 업데이트해서 특정 주소에 업로드하거나, 서버로 만들어서 내용이 자동적으로 업데이트 되도록 할 필요가 있습니다. 저는 이 글에서 다룬 내용을 Sinatra 서버로 만들어서 https://rss.mishana.kr에서 제공하고 있습니다.
공지에서도 소개했지만, 이 RSS를 Feedly에서 구독해보면, 전체 본문이 HTML로 렌더링되어 정상적으로 출력됩니다. 만족스럽네요. 😆
이렇게 처음으로 스팀잇 데이터를 사용한 프로그래밍에 도전해보았는데 생각보다 데이터에 쉽게 접근할 수 있어서 큰 어려움은 없었습니다. 심지어 데이터에 접근하는데 인증조차도 필요하지 않았습니다. 이 데이터들을 사용하면 자신의 RSS를 만드는 것 뿐만 아니라, 타임라인 RSS나 다른 저자 분의 RSS나 태그에 대한 RSS를 제공하는 것도 어렵지 않습니다. 태그를 가져올 수도 있고, 다양한 기준으로 필터링을 할 수도 있습니다.
범용적인 서비스로 만들어볼까도 잠깐 생각했지만 타인의 데이터를 제가 직접 제공하는 데는 저작권이나 운영 부담이 있어서 일단은 제 RSS만 공개했습니다.
관심 있으시면 꼭 도전해보길 바랍니다. 오늘도 즐거운 하루 되세요 ;)
최근에 공개한 글 목록입니다.
- <공지> 이 스팀잇의 RSS 피드를 지원합니다
- <회고> 2018년 1주차: 스팀잇 뉴비 1주일 생존기
- <투자 이야기> 투자 수익률의 이해 1편: 두 기간의 평균 수익률과 기하평균
- <책으로 배우는 투자> 존 리, 엄마, 주식 사주세요
- <투자 이야기> 일본 주식 투자: 유니클로에 투자하려면 필요한 최소 금액은?

글쓰고, 프로그래밍하고, 투자하는 @mishana입니다. 트위터 @mishan__a.
- 저는 투자를 권유하지 않습니다. 각자의 선택이고, 결과는 각자의 몫입니다 ;)
- 이 글이 도움이 되셨다면 리스팀, 팔로우 부탁드려요 :)