
Introduction
This informative series of posts will explore modern biology; the fundamental principles of how living systems work. This material will always be presented at the level of a first-year college biology course, without assuming any prior background in biology or science. It also presents material in a conceptual format. Emphasizing the importance of broad, unifying principles, facts and details in the context of developing an overarching framework. Finally, the series takes a historical approach wherever possible. Explaining how key experiments and observations led to our current state of knowledge and introducing many of the people responsible for creating the modern science of biology.
This post shifts the focus on DNA from its remarkable ability to be copied accurately to the inevitable mistakes that happen when copying occurs.
Not only is the copying process prone to error, but DNA is a fragile molecule that can be damaged by a number of external forces. This post discusses the causes for errors that creep into DNA and the mechanisms that have evolved to detect and repair those errors, when possible. Errors in the DNA code sometimes go unrepaired, however, and such errors can lead to unfortunate outcomes, including cancer. In other, less deleterious cases, errors provide the fodder for evolution by natural selection.
In spite of the extraordinary coordination, precision, and elegance of the molecular machinery used in the task of DNA replication, errors can and do occur.
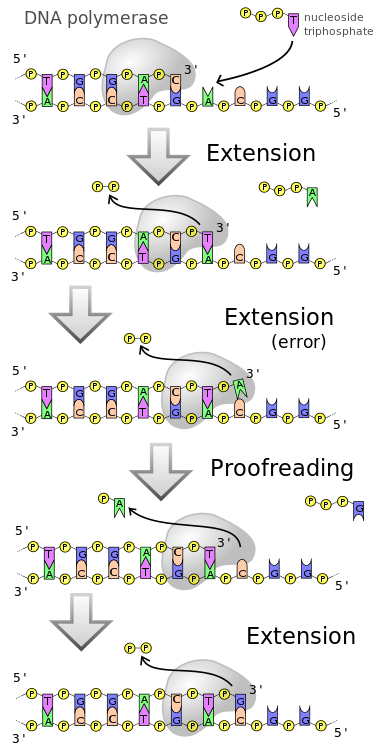
For example, DNA polymerase might fail to insert an appropriate complementary base, or DNA might be damaged. We call these errors mutations. In most cases, base pair mismatches are detected and repaired immediately. The number of errors remaining after the replication process is complete is very low, on the order of 1 mismatch for every 1 billion nucleotides. The number of errors made during the replication process, on the other hand, might be 1 mismatch for every 10,000 base pairs. This number may not seem large, but it represents an enormous number of errors when summed over the entire genome of an organism.
The difference is due to mismatch repair mechanisms associated with the replication process that detect errors shortly after they occur and replace an incorrectly matched base with a correct one.
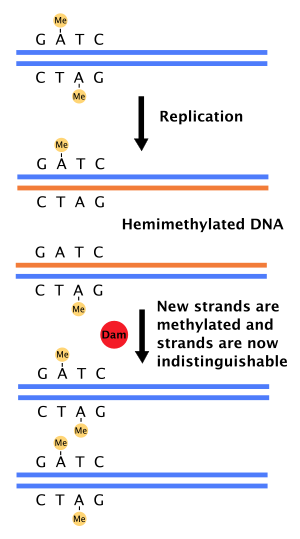
DNA polymerase has its own error-checking process and usually replaces an incorrect base with the correct one. This lowers the error rate to about 1 in 10 million. This is still quite high, given that a human genome has about 3.2 billion base pairs. Mismatch repair enzymes constantly inspect newly synthesized DNA for incorrect base pairings. When they discover a mistake, they cut out the incorrect base or section and let DNA polymerase replace the section. As a result of complementary base pairing finding errors should be simple, but determining the correct replacement is very difficult because there is no way to know which base in a pair is the correct one. Molecular biologists discovered that DNA is gradually methylated as it ages, and mismatch repair enzymes use differences in methylation to determine which base is correct and which is not. Although the final error rate of 1 mismatch in 1 billion base pairs is quite small, these mistakes add up in potentially harmful ways.
Mutations can also be introduced to DNA outside the replication process. DNA is a relatively fragile molecule, and a number of physical and chemical agents can break, modify, or otherwise damage the strand.
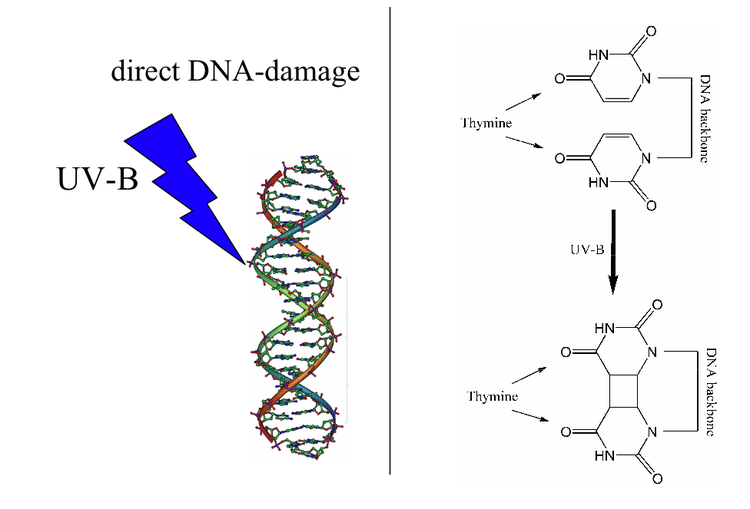
- Ultraviolet (UV) light, X-rays, or other kinds of radiation are absorbed by nucleotides and may cause chemical bonds to break. This bond breakage can damage bases or base pairs or break apart entire DNA molecules.
- Reactive chemicals (such as aflatoxin, free radicals, and chemicals found in tobacco smoke) can also break chemical bonds in DNA.
By one estimate, the DNA in a single human cell may be damaged in one or more of these ways a thousand times per day.
Outside of the replication process, DNA is constantly being examined for errors; when errors are detected, dozens of different types of excision repair enzymes attempt to repair the damage.
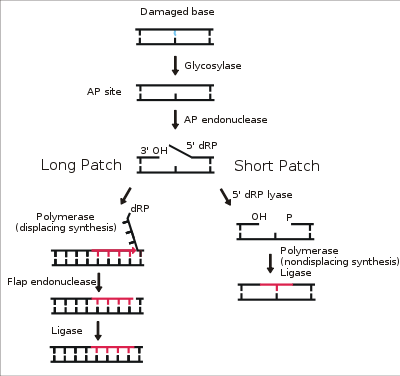
Excision repair generally involves a suite of enzymes that cut out a stretch of the damaged strand of DNA around the site of the error, then resynthesize a new segment of DNA in its place using the complementary, undamaged DNA strand as a template. Despite these error-correcting mechanisms, some damage goes unrepaired. Many cancers are caused by genetic mutations to oncogenes (or tumor suppressor genes) caused by exposure to DNA-damaging agents. Oncogenes regulate cell growth and division; when damaged, cells begin to divide uncontrollably.
A genetic disease called xeroderma pigmentosum affects about 1 in every 250,000 people in the United States. 60% of people with this affliction do not survive past the age of 20
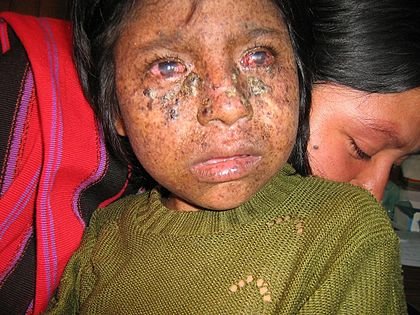
Affected individuals are unusually sensitive to UV light from the sun. Normal individuals can develop cancer from prolonged exposure to UV light, but people with xeroderma pigmentosum can develop the same problems from only brief exposures. Genetic analysis of xeroderma pigmentosum patients has revealed that they all lack one or more excision repair enzymes and cannot repair UV damage. DNA polymerase would normally repair this damage in a process referred to as nucleotide excision repair. In individuals with xeroderma pigmentosum mutations of nucleotide excision repair (NER) enzymes can interfere with or even eliminate NER entirely.
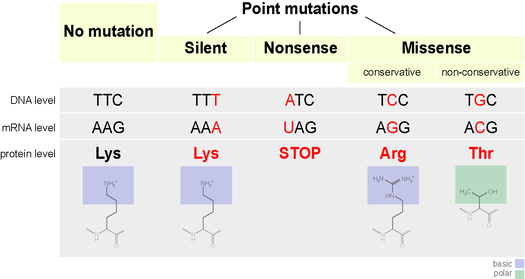
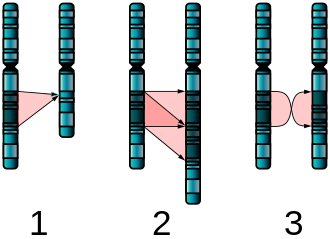
Types of mutations include point mutations, insertion or deletion mutations, and chromosomal mutations.
* Point mutations involve only the substitution of one base for another.
* Insertion or deletion mutations involve the insertion or deletion of a base pair in a DNA molecule.
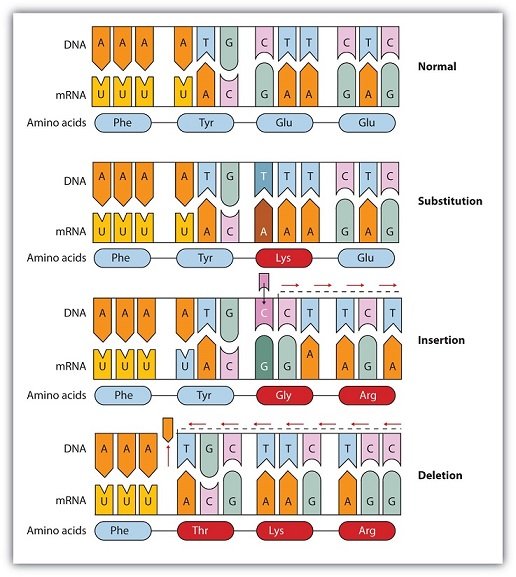
* Chromosomal mutations involve the deletion, inversion, duplication, or rearrangement of large sections of DNA and occur when the double helix is broken apart.
Mutations can be deleterious but are not necessarily so.
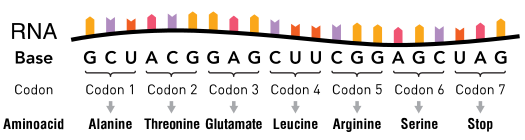
Some point mutations are silent, meaning that they do not affect the amino acid sequence; in other cases, a mutation may affect amino acid sequence but not in a way that affects a protein’s structure (and, therefore, function). These kinds of mutations are essentially neutral. Mutations that do change protein shape and function can render the protein dysfunctional. Such changes in protein structure and function can be lethal. Occasionally, a mutation may change the structure and function of a protein in a slightly advantageous way.
Unrepaired mutations in DNA, if they do not have a measurably deleterious effect, provide a source of genetic variation in a population.
Genetic variation, in turn, provides the essential substrate on which natural selection and other evolutionary processes act. The only types of mutations that matter for evolution are ones that can be passed on to offspring. For single-celled organisms, every mutation may be passed on. Multicellular organisms typically have a small number of reproductive cells (germ-line cells), and mutations in the other (somatic) cells will not be transmitted to offspring. Some DNA repair enzymes may actually introduce a change in an otherwise “correct” sequence of bases.
END PART 13
CONCLUSION OF INFORMATION THEME
NEXT THEME EVOLUTION
BIOLOGY THE STUDY OF LIFE:
[1-13 INFORMATION]
PART 1 INTRODUCTION
PART 2 WHAT IS LIFE
PART 3 ORIGIN OF LIFE
PART 4 CELL TO ORGANISM
PART 5 PROTEINS
PART 6 CODE OF LIFE
PART 7 DOUBLE HELIX
PART 8 REPLICATING DNA
PART 9 CENTRAL DOGMA
PART 10 GENETIC CODE
PART 11 DNA TO RNA
PART 12 RNA TO PROTEINS
PART 13 MISTAKES HAPPEN

 or
or  @pjheinz
@pjheinzImage Credits:
ALL IMAGES UNLESS NOTED - Wikipedia